首先我们得明确3D引擎使用多线程的目的所在:
1、在CPU上进行的逻辑计算(比如骨骼动画粒子发射等)不影响渲染速度
2、较差的GPU渲染速度的低下不影响逻辑速度
第一个目标已经很明确了,我来解释下需要达到第二个目标的原因:许多动作游戏的逻辑判定是基于帧的,所以在渲染较慢的情况下,逻辑不能跳帧,而仍然需要严格执行才能保证游戏逻辑的正确性,这就导致了游戏速度的放慢,而实际上个人认为渲染保持15帧以上就已经可以正常进行游戏了。
在较差的GPU上跑《鬼泣4》《刺客信条》《波斯王子4》简直就像是慢镜头一样,完全没法玩。而实际上CPU跑满帧是没有问题的,如果能把逻辑帧和渲染帧彻底分离,即使渲染帧达不到要求,但CPU仍能正确的执行游戏逻辑,就可以解决动作游戏对GPU要求过高的问题。
我们先来看多线程Ogre的两种架构,第一种是middle-level multithread
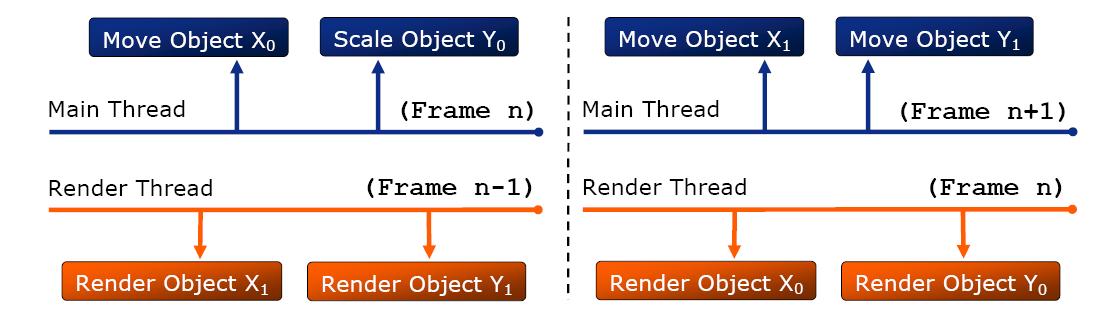
如上图所示,每个需渲染的实体被复制成了两份,主线程和渲染线程交替更新和渲染同一个实体的两个备份,并在一帧结束时同步,这种解决方案达到了第一个目标而并没有达到第二个目标,同时两份实体的维护也相对复杂,并且没法为更多核数的CPU进行扩展优化。
第二种Ogre多线程的方法是 low-level multithread
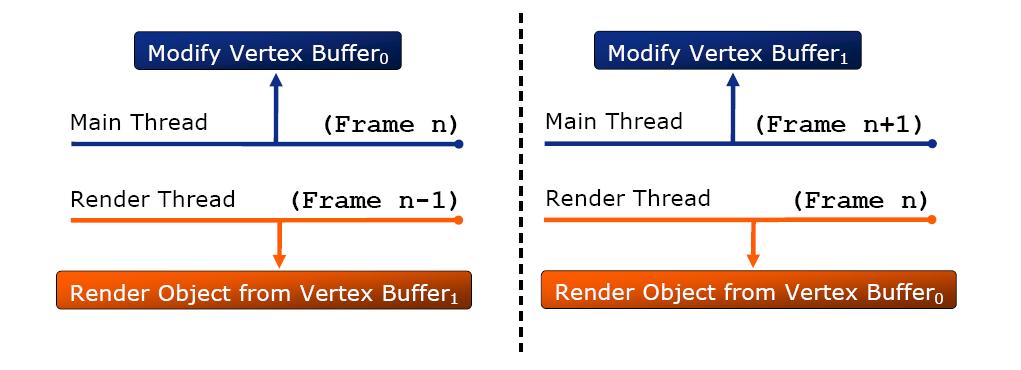
如图,将D3D对象复制两份,同样是在帧结束时同步并交换,和上面的优缺点类似。两种多线程Ogre的解决方案都是在引擎层完成的,对上层应用透明,对于用户而言无需考虑多线程细节,这点是非常不错的。
接下来我们来看SIGGRAPH2008上,id soft提出的多线程3D引擎的方案
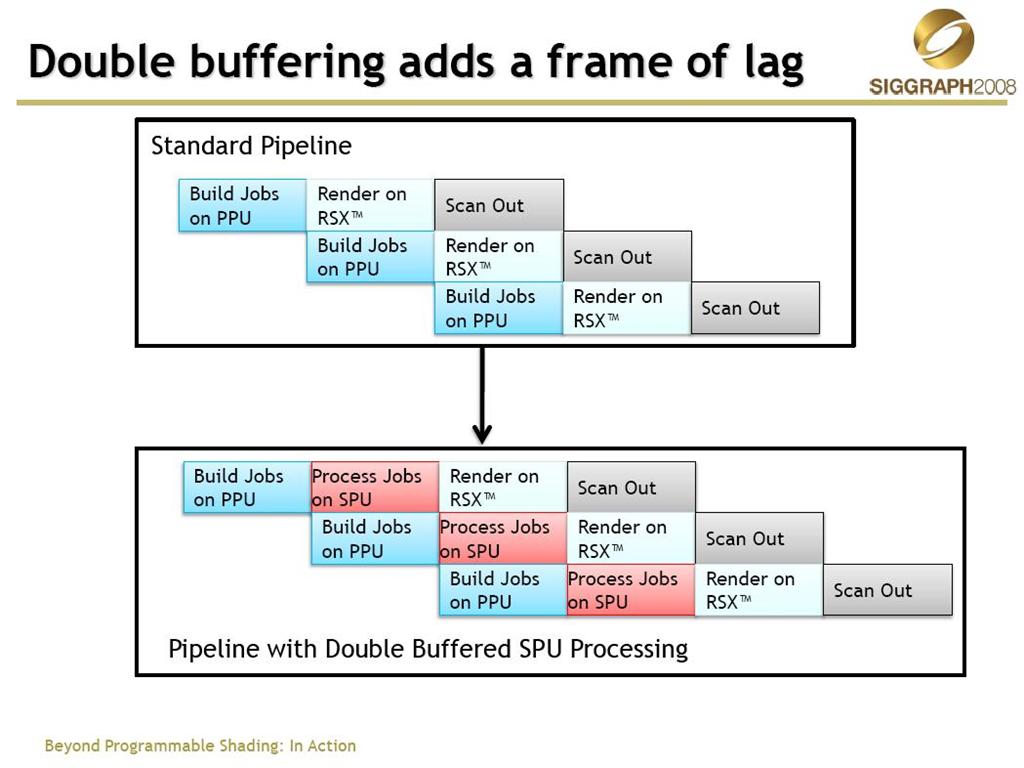
这里是已PS3的引擎结构为例的,与PC有较大的差别,其中SPU是Cell芯片的8个协处理器,拥有强大的并行能力,id的解决方案在SPU上进行了诸如骨骼动画、形变动画、顶点和索引缓存的压缩、Progressive Mesh的计算等诸多内容,同时与PPU上的物理计算RSX上的渲染工作交错进行,最大化的利用了PS3的硬件结构,最终的游戏产品《Rage》很快就会面世了!
最后是我的解决方案
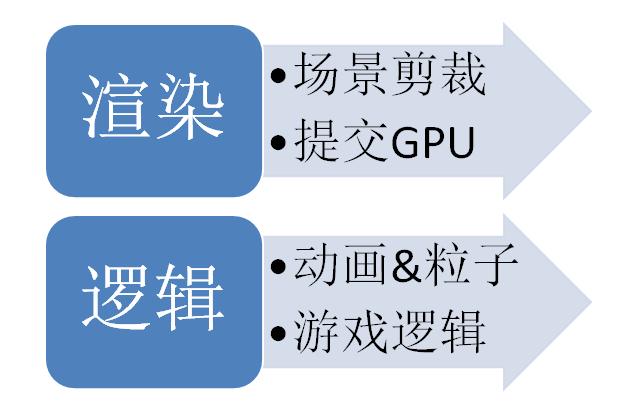
特点是逻辑完全分离,无需同步,虽然成功的达到了文章开始提出的两个目标,但对于引擎的使用者必须考虑多线程的诸多问题,各种计算需放在哪个线程,如何在两个线程间交互,都需要深入思考,所以要应用到实际的游戏制作,恐怕还有很长的一段路要走。
结合目前的架构和上面看到的几种多线程架构,同时也为了迎接DX11的到来,我准备将我的方案进一步改进成如下所示
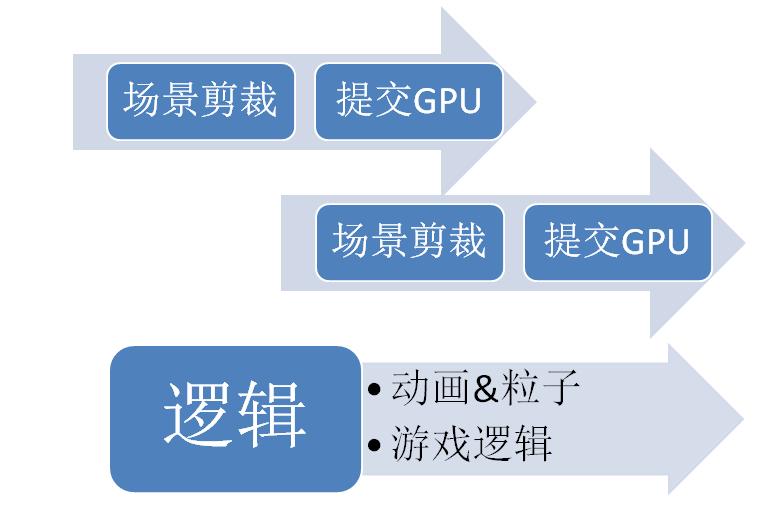
场景剪裁与提交渲染交替进行,并在渲染帧末进行一次同步,而多个渲染表面的场景剪裁可再并行执行。
图片多,文字少,需更详细资料请自行google,本文就此结束!