摘要: lua的VM执行代码是从lvm.c中的void luaV_execute(lua_State *L)开始:Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->void luaV_execute (lua_State *L)&n...
阅读全文
posted @
2012-09-19 12:34 airtrack 阅读(7268) |
评论 (5) |
编辑 收藏C的NULL
在C语言中,我们使用NULL表示空指针,也就是我们可以写如下代码:
int *i = NULL;
foo_t *f = NULL;
实际上在C语言中,NULL通常被定义为如下:
#define NULL ((void *)0)
也就是说NULL实际上是一个void *的指针,然后吧void *指针赋值给int *和foo_t *的指针的时候,隐式转换成相应的类型。而如果换做一个C++编译器来编译的话是要出错的,因为C++是强类型的,void *是不能隐式转换成其他指针类型的,所以通常情况下,编译器提供的头文件会这样定义NULL:
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
C++的0
因为C++中不能将void *类型的指针隐式转换成其他指针类型,而又为了解决空指针的问题,所以C++中引入0来表示空指针,这样就有了类似上面的代码来定义NULL。实际上C++的书都会推荐说C++中更习惯使用0来表示空指针而不是NULL,尽管NULL在C++编译器下就是0。为什么C++的书都推荐使用0而不是NULL来表示空指针呢?我们看一个例子:
在foo.h文件中声明了一个函数:
void bar(sometype1 a, sometype2 *b);
这个函数在a.cpp、b.cpp中调用了,分别是:
a.cpp:

bar(a, b);
b.cpp:
bar(a, 0);
好的,这些代码都是正常完美的编译运行。但是突然在某个时候我们功能扩展,需要对bar函数进行扩展,我们使用了重载,现在foo.h的声明如下:
void bar(sometype1 a, sometype2 *b);
void bar(sometype1 a, int i);
这个时候危险了,a.cpp和b.cpp中的调用代码这个时候就不能按照期望的运行了。但是我们很快就会发现b.cpp中的0是整数,也就是在overload resolution的时候,我们知道它调用的是void bar(sometype1 a, int i)这个重载函数,于是我们可以做出如下修改让代码按照期望运行:
bar(a, static_cast<sometype2 *>(0));
我知道,如果我们一开始就有bar的这两个重载函数的话,我们会在一开始就想办法避免这个问题(不使用重载)或者我们写出正确的调用代码,然而后面的这个重载函数或许是我们几个月或者很长一段时间后加上的话,那我们出错的可能性就会加大了不少。貌似我们现在说道的这些跟C++通常使用0来表示空指针没什么关系,好吧,假设我们的调用代码是这样的:
foo.h
void bar(sometype1 a, sometype2 *b);
a.cpp
bar(a, b);
b.cpp
bar(a, NULL);
当bar的重载函数在后面加上来了之后,我们会发现出错了,但是出错的时候,我们找到b.cpp中的调用代码也很快可能忽略过去了,因为我们用的是NULL空指针啊,应该是调用的void bar(sometype1 a, sometype2 *b)这个重载函数啊。实际上NULL在C++中就是0,写NULL这个反而会让你没那么警觉,因为NULL不够“明显”,而这里如果是使用0来表示空指针,那就会够“明显”,因为0是空指针,它更是一个整形常量。
在C++中,使用0来做为空指针会比使用NULL来做空指针会让你更加警觉。
C++ 11的nullptr
虽然上面我们说明了0比NULL可以让我们更加警觉,但是我们并没有避免这个问题。这个时候C++ 11的nullptr就很好的解决了这个问题,我们在C++ 11中使用nullptr来表示空指针,这样最早的代码是这样的,
foo.h
void bar(sometype1 a, sometype2 *b);
a.cpp
bar(a, b);
b.cpp
bar(a, nullptr);
在我们后来把bar的重载加上了之后,代码是这样:
foo.h
void bar(sometype1 a, sometype2 *b);
void bar(sometype1 a, int i);
a.cpp
bar(a, b);
b.cpp
bar(a, nullptr);
这时候,我们的代码还是能够如预期的一样正确运行。
在没有C++ 11的nullptr的时候,我们怎么解决避免这个问题呢?我们可以自己实现一个(《Imperfect C++》上面有一个实现):
const
class nullptr_t
{
public:
template<class T>
inline operator T*() const
{ return 0; }
template<class C, class T>
inline operator T C::*() const
{ return 0; }
private:
void operator&() const;
} nullptr = {};
虽然这个东西被大家讨论过很多次了,但是我觉得还是有必要再讨论一下,毕竟在C++ 11还没有普及之前,我们还是应该知道怎么去避免问题,怎么很快的找到问题。
posted @
2012-09-16 01:08 airtrack 阅读(18165) |
评论 (3) |
编辑 收藏接上一篇:lua源码剖析(一)
词法分析
lua对与每一个文件(chunk)建立一个LexState来做词法分析的context数据,此结构定义在llex.h中。词法分析根据语法分析的需求有当前token,有lookahead token,LexState结构如图:
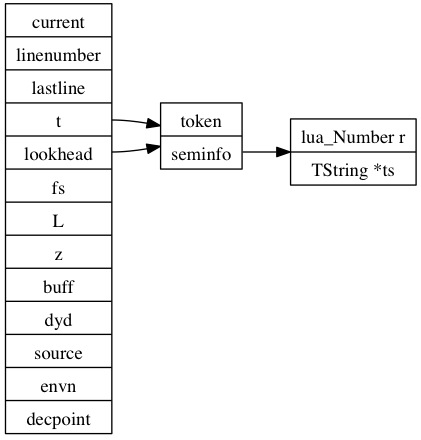
其中token结构中用int存储实际token值,此token值对于单字符token(+ - * /之类)就表示自身,对于多字符(关键字等)token是起始值为257的枚举值,在llex.h文件中定义:
#define FIRST_RESERVED 257
/*
* WARNING: if you change the order of this enumeration,
* grep "ORDER RESERVED"
*/enum RESERVED {
/* terminal symbols denoted by reserved words */ TK_AND = FIRST_RESERVED, TK_BREAK,
TK_DO, TK_ELSE, TK_ELSEIF, TK_END, TK_FALSE, TK_FOR, TK_FUNCTION,
TK_GOTO, TK_IF, TK_IN, TK_LOCAL, TK_NIL, TK_NOT, TK_OR, TK_REPEAT,
TK_RETURN, TK_THEN, TK_TRUE, TK_UNTIL, TK_WHILE,
/* other terminal symbols */ TK_CONCAT, TK_DOTS, TK_EQ, TK_GE, TK_LE, TK_NE, TK_DBCOLON, TK_EOS,
TK_NUMBER, TK_NAME, TK_STRING
};
token结构中还有一个成员seminfo,这个表示语义信息,根据token的类型,可以表示数值或者字符串。
lex提供函数luaX_next和luaX_lookahead分别lex下一个token和lookahead token,在内部是通过llex函数来完成词法分析。
语法分析
lua语法分析是从lparser.c中的luaY_parser开始:
Closure *luaY_parser (lua_State *L, ZIO *z, Mbuffer *buff,
Dyndata *dyd, const char *name, int firstchar) {
LexState lexstate;
FuncState funcstate;
Closure *cl = luaF_newLclosure(L, 1); /* create main closure */
/* anchor closure (to avoid being collected) */
setclLvalue(L, L->top, cl);
incr_top(L);
funcstate.f = cl->l.p = luaF_newproto(L);
funcstate.f->source = luaS_new(L, name); /* create and anchor TString */
lexstate.buff = buff;
lexstate.dyd = dyd;
dyd->actvar.n = dyd->gt.n = dyd->label.n = 0;
luaX_setinput(L, &lexstate, z, funcstate.f->source, firstchar);
mainfunc(&lexstate, &funcstate);
lua_assert(!funcstate.prev && funcstate.nups == 1 && !lexstate.fs);
/* all scopes should be correctly finished */
lua_assert(dyd->actvar.n == 0 && dyd->gt.n == 0 && dyd->label.n == 0);
return cl; /* it's on the stack too */
}
此函数创建一个closure并把LexState和FuncState初始化后调用mainfunc开始parse,其中FuncState表示parse时函数状态信息的,如图:
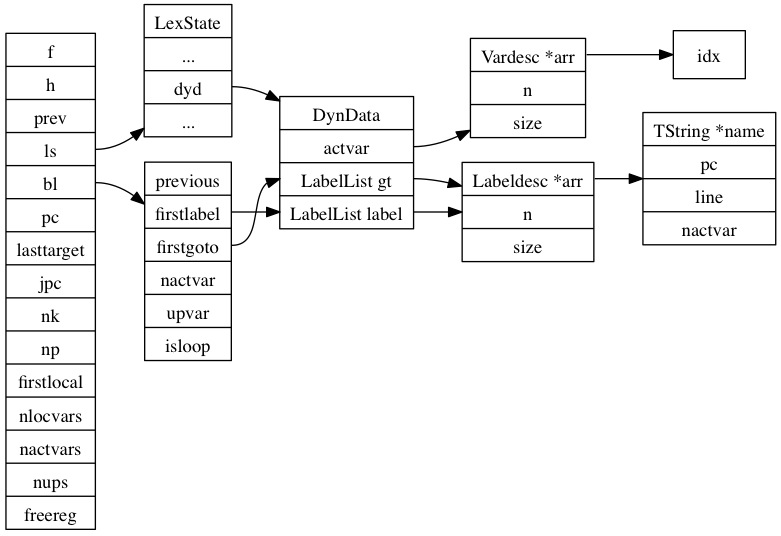
每当parse到一个function的时候都会建立一个FuncState结构,并将它与所嵌套的函数通过prev指针串联起来,body函数就是完成嵌套函数parse。
static void body (LexState *ls, exposed *e, int ismethod, int line) {
/* body -> `(' parlist `)' block END */
FuncState new_fs;
BlockCnt bl;
new_fs.f = addprototype(ls);
new_fs.f->linedefined = line;
open_func(ls, &new_fs, &bl);
checknext(ls, '(');
if (ismethod) {
new_localvarliteral(ls, "self"); /* create 'self' parameter */
adjustlocalvars(ls, 1);
}
parlist(ls);
checknext(ls, ')');
statlist(ls);
new_fs.f->lastlinedefined = ls->linenumber;
check_match(ls, TK_END, TK_FUNCTION, line);
codeclosure(ls, e);
close_func(ls);
}
FuncState中的f指向这个函数的Proto,Proto中保存着函数的指令、变量信息、upvalue信息等其它信息,Proto的结构如图:
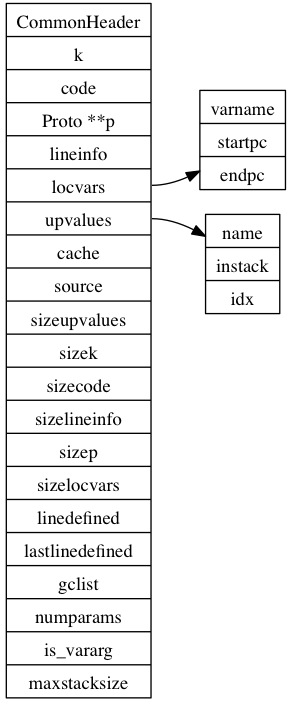
k指向一个这个Proto中使用到的常量,code指向这个Proto的指令数组,Proto **p指向这个Proto内部的Proto列表,locvars存储local变量信息,upvalues存储upvalue的信息,cache指向最后创建的closure,source指向这个Proto所属的文件名,后面的size*分别表示前面各个指针指向的数组的大小,numparams表示固定的参数的个数,is_vararg表示这个Proto是否是一个变参函数,maxstacksize表示最大stack大小。
FuncState中的ls指向LexState,在LexState中有一个Dyndata的结构,这个结构用于保存在parse一个chunk的时候所存储的gt label list和label list以及所有active变量列表,其中gt label list存储的是未匹配的goto语句和break语句的label信息,而label list存储的是已声明的label。待出现一个gt label的时候就在label list中查找是否有匹配的label,若出现一个label也将在gt label list中查找是否有匹配的gt。
LuaY_parser调用mainfunc开始parse一个chunk:
static void mainfunc (LexState *ls, FuncState *fs) {
BlockCnt bl;
expdesc v;
open_func(ls, fs, &bl);
fs->f->is_vararg = 1;
/* main function is always vararg */ init_exp(&v, VLOCAL, 0);
/* create and */ newupvalue(fs, ls->envn, &v);
/* set environment upvalue */ luaX_next(ls);
/* read first token */ statlist(ls);
/* parse main body */ check(ls, TK_EOS);
close_func(ls);
}
在mainfunc中通过open_func函数完成对进入某个函数进行parse之前的初始化操作,每parse进一个block的时候,将建立一个BlockCnt的结构并与上一个BlockCnt连接起来,当parse完一个block的时候就回弹出最后一个BlockCnt结构。BlockCnt结构中的其它变量的意思是:nactvar表示这个block之前的active var的个数,upval表示这个block是否有upvalue被其它block访问,isloop表示这个block是否是循环block。mainfunc中调用statlist,statlist调用statement开始parse语句和表达式。
statement分析语句采用的是LL(2)的递归下降语法分析法。在statement里面通过case语句处理各个带关键字的语句,在default语句中处理赋值和函数调用的分析。语句中的表达式通过expr函数处理,其处理的BNF如下:
exp ::= nil | false | true | Number | String | ‘...’ | functiondef |
prefixexp | tableconstructor | exp binop exp | unop exp
expr函数调用subexpr函数完成处理。
static BinOpr subexpr (LexState *ls, expdesc *v, int limit) {
BinOpr op;
UnOpr uop;
enterlevel(ls);
uop = getunopr(ls->t.token);
if (uop != OPR_NOUNOPR) {
int line = ls->linenumber;
luaX_next(ls);
subexpr(ls, v, UNARY_PRIORITY);
luaK_prefix(ls->fs, uop, v, line);
}
else simpleexp(ls, v);
/* expand while operators have priorities higher than `limit' */
op = getbinopr(ls->t.token);
while (op != OPR_NOBINOPR && priority[op].left > limit) {
expdesc v2;
BinOpr nextop;
int line = ls->linenumber;
luaX_next(ls);
luaK_infix(ls->fs, op, v);
/* read sub-expression with higher priority */
nextop = subexpr(ls, &v2, priority[op].right);
luaK_posfix(ls->fs, op, v, &v2, line);
op = nextop;
}
leavelevel(ls);
return op; /* return first untreated operator */
}
当分析exp binop exp | unop exp的时候lua采用的是算符优先分析,其各个运算符的优先级定义如下:
static const struct {
lu_byte left; /* left priority for each binary operator */
lu_byte right; /* right priority */
} priority[] = { /* ORDER OPR */
{6, 6}, {6, 6}, {7, 7}, {7, 7}, {7, 7}, /* `+' `-' `*' `/' `%' */
{10, 9}, {5, 4}, /* ^, .. (right associative) */
{3, 3}, {3, 3}, {3, 3}, /* ==, <, <= */
{3, 3}, {3, 3}, {3, 3}, /* ~=, >, >= */
{2, 2}, {1, 1} /* and, or */
};
#define UNARY_PRIORITY 8 /* priority for unary operators */
代码生成
lua代码生成是伴随着语法分析进行的,指令类型Instruction定义在llimits.h中:
/*
** type for virtual-machine instructions
** must be an unsigned with (at least) 4 bytes (see details in lopcodes.h)
*/
typedef lu_int32 Instruction;

Instruction是一个32位的整形数据,其中0~5 bits表示optype,6~13 bits参数A,14~22 bits表示参数B,23~31 bits表示参数C,14~31 bits表示参数Bx或sBx,6~31 bits表示参数Ax。
代码生成的函数声明在lcode.h中,以luaK开头,这一系列的函数大多都有expdesc *v的参数,expdesc的结构定义在lparser.h,如下:
typedef struct expdesc {
expkind k;
union {
struct { /* for indexed variables (VINDEXED) */
short idx; /* index (R/K) */
lu_byte t; /* table (register or upvalue) */
lu_byte vt; /* whether 't' is register (VLOCAL) or upvalue (VUPVAL) */
} ind;
int info; /* for generic use */
lua_Number nval; /* for VKNUM */
} u;
int t; /* patch list of `exit when true' */
int f; /* patch list of `exit when false' */
} expdesc;
expdesc中的t和f分别表示表达式为true和false时,待回填跳转指令的下标。k表示表达式的类型,u表示对应类型的数据。
代码生成过程中根据表达式类型做相应的代码生成操作,lua中每个函数最大有250个寄存器,表达式的计算就是选择这些寄存器存放并生成数据,而寄存器的下标是在代码生成阶段选择好的,寄存器的释放是根据变量和表达式的生命周期结束的时候释放。代码生成过程会将变量的生命周期的起始pc和结束指令pc分别存放在Proto中的LocVar的startpc和endpc里面,供调试使用。
posted @
2012-08-12 17:28 airtrack 阅读(8654) |
评论 (0) |
编辑 收藏很早就想读lua的源码,也曾很多次浏览过大概。不过我一直没有深入去读,一是想自己在读lua源码之前,仅凭自己对lua使用的理解自己先实现一个简单的lua子集,二是我觉得自己实现过lua的子集之后也能帮助自己更容易的理解lua源码。前段时间,花了几个月的业余时间,实现了一个简单粗糙的lua子集(https://github.com/airtrack/luna)之后,我觉得现在可以开始读lua的源码了。
从lua.c的main函数开始,lua.c是一个stand-alone的解释器,编译完就是一个交互式命令行解释器,输入一段lua代码,然后执行并返回结果,也可以执行一个lua文件。
main:
/* call 'pmain' in protected mode */
lua_pushcfunction(L, &pmain);
lua_pushinteger(L, argc); /* 1st argument */
lua_pushlightuserdata(L, argv); /* 2nd argument */
status = lua_pcall(L, 2, 1, 0);
result = lua_toboolean(L, -1); /* get result */
main函数创建了lua_State之后就按照调用C导出给lua函数的方式调用了pmain函数。pmain函数中通过lua栈获取到命令行的argc和argv参数之后,对参数进行分析后,主要可以分为两个分支,一个处理交互命令行,一个处理文件。dotty出来交互命令行,handle_script处理lua文件。
handle_script:
status = luaL_loadfile(L, fname);
lua_insert(L, -(narg+1));
if (status == LUA_OK)
status = docall(L, narg, LUA_MULTRET);
else
lua_pop(L, narg);
在handle_script中先loadfile,然后docall。
loadfile会产生一个什么东西在栈上呢?写过lua的程序的人估计都会了解到下面这段lua代码:
local f = load(filename)
f()
load会将文件chunk编译成一个function,然后我们就可以对它调用。如果我们详细看lua文档的话,这个函数可以带有upvalues,也就是这个函数其实是一个闭包(closure)。按照我自己实现的那个粗糙的lua子集的方式的话,每个运行时期的可调用的lua函数都是闭包。
#define luaL_loadfile(L,f) luaL_loadfilex(L,f,NULL)
luaL_loadfilex:
if (filename == NULL) {
lua_pushliteral(L, "=stdin");
lf.f = stdin;
}
else {
lua_pushfstring(L, "@%s", filename);
lf.f = fopen(filename, "r");
if (lf.f == NULL) return errfile(L, "open", fnameindex);
}
if (skipcomment(&lf, &c)) /* read initial portion */
lf.buff[lf.n++] = '\n'; /* add line to correct line numbers */
if (c == LUA_SIGNATURE[0] && filename) { /* binary file? */
lf.f = freopen(filename, "rb", lf.f); /* reopen in binary mode */
if (lf.f == NULL) return errfile(L, "reopen", fnameindex);
skipcomment(&lf, &c); /* re-read initial portion */
}
if (c != EOF)
lf.buff[lf.n++] = c; /* 'c' is the first character of the stream */
status = lua_load(L, getF, &lf, lua_tostring(L, -1), mode);
luaL_loadfile是一个宏,实际是luaL_loadfilex函数,在luaL_loadfilex函数中,我们发现是通过调用lua_load函数实现,lua_load的函数原型是:
LUA_API int lua_load (lua_State *L, lua_Reader reader, void *data, const char *chunkname, const char *mode);
定义在lapi.c中,它接受一个lua_Reader的函数并把data作为这个reader的参数。在luaL_loadfilex函数中传给lua_load作为reader是一个static函数getF,getF通过fread读取文件。
lua_load:
ZIO z;
int status;
lua_lock(L);
if (!chunkname) chunkname = "?";
luaZ_init(L, &z, reader, data);
status = luaD_protectedparser(L, &z, chunkname, mode);
在函数lua_load中,又将lua_Reader和data通过luaZ_init函数把数据绑定到ZIO的结构中,ZIO是buffered streams。之后调用luaD_protectedparser,此函数定义在ldo.c中,在这个函数中,我们发现它使用了构造lua_Reader和data的方式构造了调用函数f_parser和它的数据SParser,并将它们传给luaD_pcall,luaD_pcall的功能是在protected模式下用SParser数据调用f_parser函数,因此我们只需追踪f_parser函数即可。
luaD_protectedparser:
status = luaD_pcall(L, f_parser, &p, savestack(L, L->top), L->errfunc);
f_parser:
if (c == LUA_SIGNATURE[0]) {
checkmode(L, p->mode, "binary");
cl = luaU_undump(L, p->z, &p->buff, p->name);
}
else {
checkmode(L, p->mode, "text");
cl = luaY_parser(L, p->z, &p->buff, &p->dyd, p->name, c);
}
f_parser通过数据头的signature来判断读取的数据是binary还是text的,如果是binary的数据,则调用luaU_undump来读取预编译好的lua chunks,如果是text数据,则调用luaY_parser来parse lua代码。我们发现luaU_undump和luaY_parser函数的返回值都是Closure *类型,这个刚好就和我们前面预计的一样,一个chunk load之后返回一个闭包。
进入luaY_parser函数后,就调用了一个static的mainfunc开始parse lua代码。
仔细回顾上面看过的函数,我们会发现每个C文件的导出函数都会使用lua开头,如果没有lua开头的函数都是static函数。并且我们会发现lua后的大写前缀可以标识这个函数所属的文件:
luaL_loadfile luaL_loadfilex L应该是library的意思,属于lauxlib
luaD_protectedparser luaD_pcall D是do的意思,属于ldo
luaU_undump U 是undump的意思,属于lundump
luaY_parser Y 是代表yacc的意思,lua的parser最早是用过yacc生成的,后来改成手写,名字也保留下来,属于lparser
其它的lua函数也都有这个规律。
posted @
2012-07-19 18:24 airtrack 阅读(12617) |
评论 (3) |
编辑 收藏vimer、emacser的优越感
曾几何时,刚学编程没多久,网上看到一群“牛人”吹嘘说世界上有三种编辑器:一种是vim,一种是emacs,一种是其它。
当时看到各种介绍vim和emacs的文章都是顶礼膜拜的,希望自己哪天也能成为那种能玩的动“神器”。一直是水平不够或者其它原因,没学会。3年多前看到一个vim的视频,当时下狠心终于把vim学会了,当然有之前一两年断断续续学vim的基础的帮助。自从学会了vim之后我也加入到了vimer行列,终于学会了“神器”编辑器。终于可以在别人讨论其它编辑器的时候回复一句装逼的“vimer飘过”的语句。前辈们是说vim、emacs高效,因为你学会了之后,你的手不需要离开主键盘区域。其实在我看来这完全不是理由,其它编辑器的各种快捷键同样能够保证你不离开主键盘区域完成编辑功能,只不过普通编辑器不会强迫你学习快捷键,而vim和emacs是你必须学会快捷键才能够使用。这时“牛人”也许会说vim和emacs都有超强的定制性,可以定制你想要的“任何”功能。看起来是很牛逼的,vim和emacs是有不少很强力的插件,可以把它们定制的很强力,但是要说到“任何”那也只是停留在理论上。C++自动提示功能始终都是vim和emacs的痛,幸好有了clang,自动提示能力终于上了一个档次,但是那流畅程度和VA比起来还是要差一点,毕竟是基于单个文件分析(每次改动都会重新分析整个文件),不像VA那样是整个工程分析。至于C++的重构功能,到现在vim和emacs都没有很好的实现,不要说重构在C++里面没有用,至少我觉得rename和extract method还是很有用的。vim和emacs其实没有牛人吹嘘的那么神奇,当然它们确实是很优秀的编辑器。最近一段时间我在减少使用vim,是因为经常敲击ctrl键导致左手小指有时会疼痛。这个问题也许会在emacser上面更加严重,emacser都是迫切需要“脚踏板”的。
vimer和emacser的优越感是从前辈“牛人”那里听来,费劲力气学会,终于可以对没学会的人来上一句“你的编辑器是其它”产生的。
苹果系的优越感
苹果的产品通常比一般的产品有着更贵的价格,通常用户体验比起一般的产品也确实要好,这往往成为某些装逼人事的装逼利器。当一部分人用上了“先进”的苹果产品,开始写各种文章炫耀苹果的优越性,比起其它怎么怎么好,使得很多没有试用过苹果产品的人心生向往,费尽力气也要体验体验。当这些人费尽力气使用了苹果的产品后,有很大一部分人自然的觉得自己用上了高端的产品,往往产生优越感。有不少使用Macbook Pro的人说使用Macbook Pro再也没有关过机,什么东西都是合上就走,并以此产生对Windows的优越感,说Windows是不可能做到。然而我身边就有一个同事使用thinkpad,装的是Windows XP,而他的机器一年都是没关过机,都是合上就走的,这更别说Windows 7了。我自己从去年开始使用Macbook air,刚开始使用第一周死过一次机,后来也出现过一次死机。我觉得Macbook air是不错,但是还不至于说甩开其它产品几条街,让人产生强烈的优越感。
使用苹果系的人产生优越感往往是因为自己付出了比较大的一部分资金后,看到产品的不少优点之后就开始无视对于其它产品的缺点,从而产生一种高贵的优越感。
Linux程序员的优越感
有不少Linux程序员,觉得自己是Linux程序员能干不少牛逼的事,能看到优秀的源码。就连调用系统调用都能产生优越感,说Linux的系统调用简单明了,比起Windows的API来说简单。这当然是个优点,但这就能让人产生优越感。而往往即懂Windows又懂Linux的人的却能够更好更正确的认识各个系统的优缺点。我了解到一些Linux程序员会产生优越感,有不少是曾今学习Windows编程,发现自己没能学好(往往是学习GUI编程没学好),然后看到很多网上牛人都使用Linux,然后转移到Linux潜心学习,编写命令行程序,终于修炼成功,之后就开始喷Windows多么不好,进而产生优越感。
C程序员的优越感
C程序员的优越感的产生有点类似Linux程序员,而往往C程序员也就是Linux程序员。有了Linux的优越感之后,更加的认为只要有Linux和C就能解决所有问题,只要比C更复杂的东西都是不值得的。而这些C程序员自然而然的把优越感产生建立在C++之上,而且是这个也是有一定的相似性,也是带着C的思维学习C++,发现不少C++的东西不是按照他想象的那样运作之后,就开始鄙视C++最终又回归为C,而往往也产生对C++程序员的优越感。不过再我看来,如果能够成为一个优秀的C++程序员,你让他回去写C代码,他同样能够写出优秀的C代码来。C程序员的优越感其实有些可悲,往往是自己短视,可以不喜欢不使用一种语言,但是这完全不是产生优越感的理由。
技术等级的优越感
一般公司都有技术等级之分,高级工程师一般工作经验比普通工程师要丰富一点,抑或是在某些方面比较擅长。而他们对待普通工程师的时候往往产生一种“我什么都应该比普通工程师懂的优越感”,跟普通工程师讨论问题的时候往往带着一种高级工程师的优越感,觉得普通工程师的各个方面都不如自己的感觉,因而形成一种严格的等级制度,时间长了之后就变成了一种“文化”。这种优越感似乎是有传递性的,等那些普通工程师终于熬成高级之后也开始对后来的普通工程师产生优越感。
还有其它不少情况很多人会对某些人某些东西产生优越感,这种优越感的产生一般都是因为付出了更多的某样东西之后,自然的对事物的分级而产生,觉得自己的层级更高一点,自然而然的产生了优越感。当这种优越感开始在一定范围内开始传播之后,对于某些曾今不能体会到优越感的人同样付出了更多的某样东西之后,像病毒式的也感染了这种优越感。使得这种优越感一直往下传递。
最近发现身边和网上不少这种优越感案例,有感而发,寥寥几笔。
posted @
2012-05-15 19:17 airtrack 阅读(4295) |
评论 (21) |
编辑 收藏
摘要: BitWave的Host:
源码放在github上,采用NEW BSD LICENSE发布。地址:https://github.com/airtrack/bitwave
阅读全文
posted @
2011-05-29 17:39 airtrack 阅读(4752) |
评论 (8) |
编辑 收藏用Lua也有大半年了,从用Lua开始就想写个Lua调试器,不过由于种种原因没写,这周上班抽了点时间写了(我承认上班偷懒了,不过多是休息时间)。(点此下载)
Lua本身没有提供调试器,不过它自带了一个debug库,提供了基本的变量值获取和代码执行hook,有了这些基本功能要写一个调试器不难。
此调试器根据调试方式分为normal、step in、step over、next line四种mode,分别对应断点、步进、跳出函数、执行下行的功能。断点类型分为行断点和函数断点,分别在执行到相应行和相应函数的时候断下。在断下的时候就可以打印和修改变量,通过建立一个新的chunk并将环境设置成相应函数的环境,再执行chunk来获取和修改变量。
因为是命令行的,在命令行还没有机会添加断点的时候,要添加断点就要通过debugger.addfuncbreak和debugger.addlinebreak来添加函数和行断点,通常Lua是用于C++的脚本语言,因此程序通常是有一个可以直接执行Lua脚本指令的入口,这样的入口就可以打下第一个断点,这样在断下断点后就可以在命令提示符下做所有的操作了。
代码是上班抽时间写的,写的很随意,也没多少注释,权当玩具吧。目前的功能基本能满足我的要求了,也不打算继续改进了。调试器是用来帮助找错误,不要过分依赖调试器。Robert C. Martin说Debuggers are a wasteful Timesink。虽说有些偏激,但是不无道理。
posted @
2011-01-01 01:44 airtrack 阅读(4854) |
评论 (3) |
编辑 收藏