摘要: 免费引擎
Agar - 一个高级图形应用程序框架,用于2D和3D游戏。
Allegro library - 基于 C/C++ 的游戏引擎,支持图形,声音,输入,游戏时钟,浮点,压缩文件以及GUI。
Axiom 引擎 - OGRE的衍生引擎。
Baja 引擎 - 专业品质的图像引擎,用于The Lost Mansion。
Boom - Doom代...
阅读全文
posted @
2008-06-23 23:04 谢岱唛 阅读(808) |
评论 (0) |
编辑 收藏
首先,二话不说,上图(用Windows画图画的。。。)
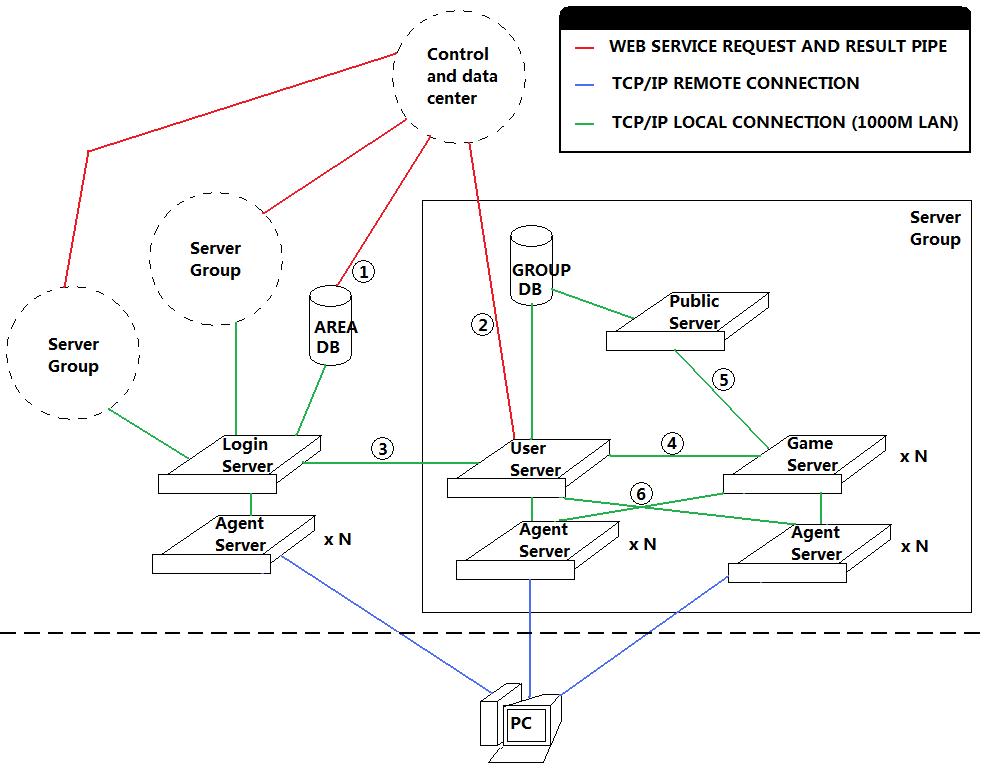
这个图是一个区的架构图,所有区的架构是一样的。上面虚线框的ServerGroup和旁边方框内的架构一样。图上的所有x N的服务器,都是多台一起的。红线,绿线,和蓝线图上也有图示,这里就不多介绍了。关于Agent Server大家也能看出来,其实就是Gate。
这里主要介绍下图上的标记了号码的位置的数据连接的内容和意义。
1- 这是一条WebService的管道,在用户激活该区帐号,或者修改帐号密码的时候,通过这条通道来插入和更新用户的帐号信息。
2- 这也是一条WebService管道,用来获取和控制用户该该组内的角色信息,以及进行付费商城代币之类的更新操作。
3- 这是一条本地的TCP/IP连接,这条连接主要用来进行服务器组在登陆服务器的注册,以及登陆服务器验证帐户后,向用户服务器注册帐户登陆信息,以及进行对已经登陆的帐户角色信息进行操作(比如踢掉当前登陆的角色),还有服务器组的信息更新(当前在线玩家数量等)。
4- 这也是一条本地TCP/IP连接,这条连接用来对连接到GameServer的客户端进行验证,以及获取角色数据信息,还有传回GameServer上角色的数据信息改变。
5- 这条连接也是一条本地的TCP/IP连接,它用来进行公共信息服务器和数个游戏服务器间的交互,用来交换一些游戏世界级的信息(比如公会信息,跨服组队信息,跨服聊天频道等)。
6- 这里的两条连接,想表达的意思是,UserServer和GameServer的Agent是可以互换使用的,也就是玩家进入组内之后,就不需要再切换Agent。如果不怕乱套,也可以把登陆服务器的Agent也算上,这样用户整个过程里就不需要再更换Agent,减少重复连接的次数,也提高了稳定性。(毕竟连接次数少了,也降低了连不上服务器的出现几率)
在这个架构里面,GameServer实际上是一个游戏逻辑的综合体,里面可以再去扩展成几个不同的逻辑服务器,通过PublicServer进行公共数据交换。
UserServer实际上扮演了一个ServerGroup的领头羊的角色,它负责向LoginServer注册和更新服务器组的信息(名字,当前人数),并且对Agent进行调度,对选择了该组的玩家提供一个用户量最少的Agent。同时,它也兼了一个角色管理服务器的功能,发送给客户端当前的角色列表,角色的创建,删除,选择等管理操作,都是在这里进行的。而且,它还是一个用户信息的验证服务器,GameServer需要通过它来进行客户端的合法性验证,以及获取玩家选择的角色数据信息。
采用这种架构的游戏,通常有以下表现。
1- 用户必须激活一个大区,才能在大区内登陆自己的帐号。
2- 用户启动客户端的时候,弹出一个登陆器,选择大区。
3- 用户启动真正的客户端的时候,一开始就是输入帐号密码。
4- 帐号验证完成之后,进行区内的服务器选择。
5- 服务器选择完成之后,进入角色管理。同时,角色在不同的服务器里不能共享。
市面上符合上面几个表现特征的游戏相当的多,而且也不乏旷世巨作。这个架构不是一个新的架构,但是它足够经典和完善,并且逻辑简单而清晰,用来做MMORPG,或者其它网络游戏的服务器架构,是一种不错的选择。
posted @
2008-06-23 22:53 谢岱唛 阅读(908) |
评论 (0) |
编辑 收藏目前的互联网应用,一个突出的焦点就是用户量非常大,给服务器开发和设计带来了许多挑战,这里想谈本人对这些问题的思考和体会.
大规模的多人在线系统,我接触的比较多的,有一下几种:
1. p2p 系统,p2p直播软件,在播放比较热点的节目时,会遇到数十万甚至上百万人同时观看的问题,由于p2p的特殊性质,一般不会去统一保持用户信息,
服务器需要的只是给p2p客户提供节目源, 以及为p2p 客户查找其他p2p节点提供tracker服务。所以p2p在对付大规模的人数在线时,只要简单的添加tracker
和界目源即可。这种多人在线是在软件设计时需要考虑的最少的一种。
2. 网游服务器系统。 网游服务器对付这种问题的方法是, 把整个用户空间隔离为n个世界, 譬如mmo中的某区某服, 或者休闲游戏中的房间。
当用户量不断增加时,只需不断的增加服务器组和房间服务器即可。唯一麻烦的地方,就是在于一个用户的统一认证和经济系统这块。由于这两块负载不大,
逻辑也相对简单,实现起来难度不太大。
3. IM 系统, im系统的问题就在于,他的整个用户空间,是完全统一在一起的,没法采用区服,房间的方式来隔离。当im服务器的在线人数突破10,20万之后,
设计一套集群系统就是势在必行的了。这个时候单台逻辑服务器,单台数据库已经无法满足系统的性能要求了。必须采用把数据,服务,分散在各个物理服务器内,
采用集群的方式来进行管理。
当并发人数在100万以下时,我设计的一种做法是, 后台的db部分,采用一台或者几台类似mysql proxy的服务器来统一进行访问。
db 内的数据采用按照数字账号分段,或者按照某种hash 算法进行 分块的存储。 前台的逻辑服务器,不直接和db 打交道。而是通过DB Proxy来访问数据库,
这样可以保证数据库的存储策略不透明,可以于前台的逻辑部分进行独立的变化,前台逻辑服务器,连数据库的表结构都不需要知道,只需要发送请求,去DB Proxy请求指定条件的查询和结果集就可以了。而逻辑服务器之间,当100万人以下同时在线时,逻辑服务器的数目并不会太多。这些逻辑服务器之间可以直接互联。每个逻辑服务器负责一段数字账号的逻辑处理,每个逻辑服务器向其他服务器通报自己负责的数字段范围。当遇到不是本服务器能处理的请求时,譬如给其他逻辑服务器上的用户发送文本消息时,直接转发给其他逻辑服务器即可。
DB Proxy 在db server前端,单台DB Proxy的处理能力毕竟有限,这里可能还要考虑每几台DB服务器就配置一台DB Proxy。每几台前台逻辑服务器共享一台DB Proxy. im 系统的数据库访问非常频繁,在im系统中实现数据库cache,对于性能的提高是非常有帮助的。前台逻辑服务器,也应该尽量的cache数据,减少访问DB
Proxy的次数,以提高系统的整体性能。
这里为了把客户端指引到连接指定的逻辑服务器,前台需要有Dispatch 服务器,提供逻辑服务器的地址,端口。im 客户端连接逻辑服务器前必须查询Dispatch Server,来获知逻辑服务器地址。 为了增强灵活性,可以设置一台中心服务器,。来动态的提供逻辑服务器,DB Proxy等的配置信息。以及方便进行服务器组的后台管理。
这里的设计是针对udp 的im 系统来的。tcp 的im系统,成本偏高,研究的较少。
实际的应用中,还需要一些性能测试数据的配合和运营数据,才能得出比较优化了的架构。
posted @
2008-06-23 22:46 谢岱唛 阅读(318) |
评论 (0) |
编辑 收藏
1. Reverse Engineering Code with IDA pro
2. Advanced Windows Debugging
IDA Pro站点
http://www.hex-rays.com/idapro这里是Ilfak Guifanov的站点,他是IDA Pro主要的架构和作者,ida pro目前5.2,继续更新中。
posted @
2008-06-23 22:42 谢岱唛 阅读(259) |
评论 (0) |
编辑 收藏在c++的世界里,程序设计的优雅让位于程序的稳定性、健壮性。“好程序是测出来的”这句话在C++领域里得到了充分体现。下面是我在开发中使用的测试方法,抛砖引玉,和大家交流下。
测试期间,关闭对core文件的限制,使用命令:ulimit -c unlimited
(1)开发阶段,使用cppunit维护测试用例。我一般是用于测试解析类、算法类。
从http://sourceforge.net/projects/cppunit/下载最新版本,解压,看安装文档,一般是./configure & make & make install。
下面举例说明我使用cppunit的方法。假设自己的源码位于src目录下,里面有class1.h/class1.cpp/class2.h/class2.cpp。相对src建立平级目录test存放测试工程,为class1/class2分别建立测试类文件testClass1.h/testClass2.h,建立main函数所在文件test.cpp、makefile。
testClass1.h代码如下,testClass2.h类似。

#include "class1.h"
#include <iostream>
#include "cppunit/TestRunner.h"
#include "cppunit/TestResult.h"
#include "cppunit/TestResultCollector.h"
#include "cppunit/extensions/HelperMacros.h"
#include "cppunit/BriefTestProgressListener.h"
#include "cppunit/extensions/TestFactoryRegistry.h"
#include "cppunit/TextOutputter.h"
#include "cppunit/CompilerOutputter.h"
#include "cppunit/TestCaller.h"
class testClass1:public CPPUNIT_NS::TestFixture


{

CPPUNIT_TEST_SUITE(testClass1);
CPPUNIT_TEST(testCase1);
CPPUNIT_TEST(testCase2);
CPPUNIT_TEST_SUITE_END();
public:


virtual void setUp(){}
virtual void tearDown(){}
void testCase1()
{
testClass1 a;
a.oper..;
CPPUNIT_ASSERT_EQAL(a.get..,

);

}
void testCase2()
{
CPPUNIT_ASSERT(
==
);
}

};
test.cpp代码如下:
#include "testClass1.h"
#include "testClass2.h"
#include <iostream>
#include "cppunit/TestRunner.h"
#include "cppunit/TestResult.h"
#include "cppunit/TestResultCollector.h"
#include "cppunit/extensions/HelperMacros.h"
#include "cppunit/BriefTestProgressListener.h"
#include "cppunit/extensions/TestFactoryRegistry.h"
#include "cppunit/TextOutputter.h"
#include "cppunit/CompilerOutputter.h"
#include "cppunit/TestCaller.h"
CPPUNIT_TEST_SUITE_REGISTRATION(testClass1);
CPPUNIT_TEST_SUITE_REGISTRATION(testClass1);
int main()
{
CPPUNIT_NS::TestResult controller;
CPPUNIT_NS::TestResultCollector result;
controller.addListener( &result );
CPPUNIT_NS::TestRunner runner;
runner.addTest( CPPUNIT_NS::TestFactoryRegistry::getRegistry().makeTest() );
runner.run( controller );
CPPUNIT_NS::CompilerOutputter out( &result, std::cout );
out.write();
return 0;
}
makefile文件如下:
EXE=test
SRC=test.cpp
INC_PATH=-I ../src -I (cppunit头文件的目录) -I(依赖的其他头文件路径)
LIB_PATH=-L (cppunit动态库所在的目录) -L (依赖的其他库所在目录)
LIB=-lcppunit -ldl
all:
g++ $(SRC) $(LIB_PATH) $(LIB) $(INC_PATH) -o $(EXE)
再有新的需要测试类,增加相应的测试类,稍微修改下test.cpp即可(增加一句#include,一句CPPUNIT_TEST_SUITE_REGISTRATION)。
保证开发结束后,解析类、算法类等不会有错误。
(2)白盒测试阶段。
这个基本是功能逻辑性测试,检测所有数据结构按要求变化以及保证各线程之间变化的一致性。这是最基本也是最全面的一次测试,保证测试的功能覆盖率100%。白盒测试期间可以在代码里加一些宏编译选项或者增加程序交互功能用于观察所有数据结构的变化。
保证测试完毕没有功能性、逻辑性的错误。
(3)内存测试阶段。使用valgrind检测显式内存泄漏、内存读写错误。
从http://www.valgrind.org/下载最新版本,解压,看安装文档,一般是./configure & make & make install。
检测内存一般使用命令valgrind --tool=memcheck -v --leak-check=full ./待测程序错误的地方会用==×××==(×××表示数字)标出。
使用一路模拟客户端做陪测。
保证测试完毕,单路客户端陪测的情况下没有任何的显式内存泄漏,没有任何的内存读写错误。
(4)写批量客户端模拟程序。建议熟悉一门方便socket编程的脚本语言,推荐perl。脚本语言简单,实现快速,特适合做陪测。
首先写一个能读取配置文件信息,按配置文件的要求向相应的server,按配置文件的流程发送信令的perl程序。
下面是我rtsp相关的一个server陪测的配置文件:
ip=127.0.0.1
port=9115
url=rtsp://172.24.202.190:554/asset/service?USERID=320101312345670001&ChanelNo-PUID=0-320101000200000001&PlayMethod=0
<s,2>
<p,2>
<u,2>
<p,2>
<t,2>
其中ip是server IP,port是rtsp端口,url是发送信令带的url。<>表示按顺序发送的信令,这个配置文件表示先发送一个setup,然后sleep 2秒,再发送一个play,然后sleep 2秒,继续......这个程序可作为(3)中的陪测程序
在上面程序的基础上修改,读取配置文件后,死循环按顺序发送信令,假设该程序称做B。
写一个新的perl文件,完成如下功能,起几十路使用某配置文件的B程序,sleep几秒后,再起几十路使用其它配置文件的B程序.....,或者一起起也可以,自行设计,最后killall所有,从头循环运行。
总之尽可能的模拟客户端的所有行为,包括突然断联等,并且保证一定的压力。
(5)压力下测试内存。继续在valgrind下测试,使用(4)中的测试脚本做配测。
保证压力下无异常状态、无数据不一致状态、无显式内存泄漏、无内存读写异常
(6)稳定性以及内存泄漏测试。
陪测脚本起几百路客户端,保证主程序的cpu占用率在70%以上,持续运行20多小时。
测试期间,关注进程对内存的占用率,是保持在恒定水平还是随运行时间的增长而增长。
测试完毕,保证主程序负荷运行长时间而不宕机、没有内存泄漏发生。
(7)代码覆盖率测试。gcov
gcov是随gcc安装的,可以检查陪测程序对目标程序的代码覆盖情况。
不断修改测试脚本,保证测试尽量全面。代码被执行的次数也可以做为以后性能测试的一个参考。
(8)性能测试。gprof
同gcov一样,gprof也是随gcc安装的,它可以检测目标程序中所有函数的调用时间,并根据消耗时间排序,方便找出性能瓶颈。
找出系统的主要性能瓶颈,经过性能测试后,一般会发现影响系统的主要因素还是数据结构和算法。
测试期间,任何的coredump/任何的内存读写异常,务必处理掉。墨菲法则说,一个事情如果有可能变糟,事实则是会变的更糟。任何一个微小的、出现几率极小的bug,如果不在研发测试阶段解决,都可能造成以后更大代价的返工,甚至给客户的运营带来灾难。希望在每个人身上生效的都是马太效应,而不是墨菲法则。
posted @
2008-06-23 22:00 谢岱唛 阅读(368) |
评论 (0) |
编辑 收藏1. 下载
memcache的windows稳定版,解压放某个盘下面,比如在c:\memcached
2. 在终端(也即cmd命令界面)下输入 ‘c:\memcached\memcached.exe -d install’ 安装
3. 再输入: ‘c:\memcached\memcached.exe -d start’ 启动。NOTE: 以后memcached将作为windows的一个服务每次开机时自动启动。这样服务器端已经安装完毕了。
4.下载
php_memcache.dll,请自己查找对应的php版本的文件
5. 在C:\winnt\php.ini 加入一行 ‘extension=php_memcache.dll’
6.重新启动Apache,然后查看一下phpinfo,如果有memcache,那么就说明安装成功!
memcached的基本设置:
-p 监听的端口
-l 连接的IP地址, 默认是本机
-d start 启动memcached服务
-d restart 重起memcached服务
-d stop|shutdown 关闭正在运行的memcached服务
-d install 安装memcached服务
-d uninstall 卸载memcached服务
-u 以的身份运行 (仅在以root运行的时候有效)
-m 最大内存使用,单位MB。默认64MB
-M 内存耗尽时返回错误,而不是删除项
-c 最大同时连接数,默认是1024
-f 块大小增长因子,默认是1.25
-n 最小分配空间,key+value+flags默认是48
-h 显示帮助
Memcache环境测试:
运行下面的php文件,如果有输出This is a test!,就表示环境搭建成功。开始领略Memcache的魅力把!
< ?php
$mem = new Memcache;
$mem->connect(”127.0.0.1″, 11211);
$mem->set(’key’, ‘This is a test!’, 0, 60);
$val = $mem->get(’key’);
echo $val;
?>
posted @
2008-06-23 21:47 谢岱唛 阅读(736) |
评论 (0) |
编辑 收藏