传统的系统调用是怎样的? —— int 0x80的时代
.... ;通过寄存器传参
mov $n ,eax ;将系统调用号放到eax中
int 0x80
sysenter/sysexit的出场
在一个Kernel.org的邮件列表中,有一封邮件讨论了“"Intel P6 vs P7 system call performance”,最后得出的结论是采用传统的int 0x80的系统调用浪费了很多时间(具体原因可以看参考资料1),而sysenter/sysexit可以弥补这个缺点,所以决定在linux内核中用后都替换前者(最终在2.6版本的内核中才加入了此功能,即采用sysenter/sysexit)。
在替换之前首先需要知道满足如下条件的ntel机器才会有sysenter/sysexit指令对:Family >= 6,Model >= 3,Stepping >= 3
如何用替换sysenter/sysexit替换以前的int 0x80呢?linux kenerl 需要考虑到这点:有的机器并不支持sysenter/sysexit , 于是它跟glibc说好了,“你以后调用系统调用的时候就从我给你的这个地址调用,这个地址指向的内容要么是int 0x80调用方式,要么是sysenter/sysexit调用方式,我会根据机器来选择其中一个”(kernel与glibc的配合是如此的默契),这个地址便是vsyscall的首地址。
可以将vdso看成一个shared objdect file(这个文件实际上不存在),内核将其映射到某个地址空间,被所有程序所共享。(我觉得这里用到了一个技术:多个虚拟页面映射到同一个物理页面。即内核把vdso映射到某个物理页面上,然后所有程序都会有一个页表项指向它,以此来共享,这样每个程序的vdso地址就可以不相同了)
hex108@ubuntu:~/program$ uname -a
Linux ubuntu 2.6.35-22-generic #33-Ubuntu SMP Sun Sep 19 20:34:50 UTC 2010 i686 GNU/Linux
hex108@ubuntu:~/program$ sudo sysctl -w kernel.randomize_va_space=0 //这个是必须的,否则vdso的地址是随机的(vsyscall的地址也会相应
// 地发生变化 ),在下面dd的时候就会出现错误
//dd: reading `/proc/self/mem': Input/output error
kernel.randomize_va_space = 0
hex108@ubuntu:~/program$ cat /proc/self/maps
00110000-0012c000 r-xp 00000000 08:01 260639 /lib/ld-2.12.1.so
0012c000-0012d000 r--p 0001b000 08:01 260639 /lib/ld-2.12.1.so
0012d000-0012e000 rw-p 0001c000 08:01 260639 /lib/ld-2.12.1.so
0012e000-0012f000 r-xp 00000000 00:00 0 [vdso]
0012f000-00286000 r-xp 00000000 08:01 260663 /lib/libc-2.12.1.so
00286000-00287000 ---p 00157000 08:01 260663 /lib/libc-2.12.1.so
00287000-00289000 r--p 00157000 08:01 260663 /lib/libc-2.12.1.so
00289000-0028a000 rw-p 00159000 08:01 260663 /lib/libc-2.12.1.so
0028a000-0028d000 rw-p 00000000 00:00 0
08048000-08051000 r-xp 00000000 08:01 130326 /bin/cat
08051000-08052000 r--p 00008000 08:01 130326 /bin/cat
08052000-08053000 rw-p 00009000 08:01 130326 /bin/cat
08053000-08074000 rw-p 00000000 00:00 0 [heap]
b7df0000-b7ff0000 r--p 00000000 08:01 660864 /usr/lib/locale/locale-archive
b7ff0000-b7ff1000 rw-p 00000000 00:00 0
b7ffd000-b7ffe000 r--p 002a1000 08:01 660864 /usr/lib/locale/locale-archive
b7ffe000-b8000000 rw-p 00000000 00:00 0
bffdf000-c0000000 rw-p 00000000 00:00 0 [stack]
hex108@ubuntu:~/program$ dd if=/proc/self/mem of=gate.so bs=4096 skip=$[0x12e] count=1
dd: `/proc/self/mem': cannot skip to specified offset
1+0 records in
1+0 records out
4096 bytes (4.1 kB) copied, 0.00176447 s, 2.3 MB/s
hex108@ubuntu:~/program$ file gate.so
gate.so: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked, stripped
hex108@ubuntu:~/program$ objdump -d gate.so
gate.so: file format elf32-i386
Disassembly of section .text:
ffffe400 <__kernel_sigreturn>:
ffffe400: 58 pop %eax
ffffe401: b8 77 00 00 00 mov $0x77,%eax
ffffe406: cd 80 int $0x80
ffffe408: 90 nop
ffffe409: 8d 76 00 lea 0x0(%esi),%esi
ffffe40c <__kernel_rt_sigreturn>:
ffffe40c: b8 ad 00 00 00 mov $0xad,%eax
ffffe411: cd 80 int $0x80
ffffe413: 90 nop
ffffe414 <__kernel_vsyscall>:
ffffe414: cd 80 int $0x80
ffffe416: c3 ret
syscall 才是最后的赢家?
x86 64位从AMD引进了syscall指令(我在x86 64的机器上,看到的结果是syscall取代了sysenter/sysexit(所有的系统调用用的都是syscall)),但是vdso,vsyscall的机制依旧未变,只是kernel决定只在遇到以下几个系统调用gettimeofday,time和getcpu(通过内核里vsyscall.h中enum vsyscall_num的声明看出来,或者在glibc源代码中搜索“VSYSCALL_ADDR_”(
#define VSYSCALL_ADDR_vgettimeofday 0xffffffffff600000
#define VSYSCALL_ADDR_vtime 0xffffffffff600400
#define VSYSCALL_ADDR_vgetcpu 0xffffffffff600800
))时才采用vdso机制(间接调用syscall,具体可以参看资料2),其他系统调用直接用指令syscall,原因是:
"快速系统调用指令"比起中断指令来说,其消耗时间必然会少一些,但是随着 CPU 设计的发展,将来应该不会再出现类似 Intel Pentium4 这样悬殊的差距。而"快速系统调用指令"比起中断方式的系统调用方式,还存在一定局限,例如无法在一个系统调用处理过程中再通过"快速系统调用指令"调用别的系统调用。因此,并不一定每个系统调用都需要通过"快速系统调用指令"来实现。比如,对于复杂的系统调用例如 fork,两种系统调用方式的时间差和系统调用本身运行消耗的时间来比,可以忽略不计,此处采取"快速系统调用指令"方式没有什么必要。而真正应该使用"快速系统调用指令"方式的,是那些本身运行时间很短,对时间精确性要求高的系统调用,例如 getuid、gettimeofday 等等。因此,采取灵活的手段,针对不同的系统调用采取不同的方式,才能得到最优化的性能和实现最完美的功能。 ----引自参考资料1
ps:文中的内核版本为2.6.36,glibc版本为2.11
参考资料:
1. Linux 2.6 对新型 CPU 快速系统调用的支持: http://www.ibm.com/developerworks/cn/linux/kernel/l-k26ncpu/index.html (这篇我觉得最好)
2. System Calls : http://www.win.tue.nl/~aeb/linux/lk/lk-4.html(里面有程序可以用来搜索vsyscall等的地址,很直接)
3. What is linux-gate.so.1 : http://www.trilithium.com/johan/2005/08/linux-gate/
4. Intel手册,里面有各种资料,手册还是很重要的,也是最基本的
posted @
2010-11-22 21:19 hex108 阅读(12448) |
评论 (0) |
编辑 收藏
摘要: lisp的功能还是挺强大的,简单的几行代码就搞定了一个小的“数据库”(经验:调试macro的时候可以用macroexpand-1展开该macro,看是否与设想的一样。)。
阅读全文
posted @
2010-10-01 22:23 hex108 阅读(1052) |
评论 (0) |
编辑 收藏最近《hackers & painters》学到的印象最深的一点是:lisp比你想像中的还强大,用lisp吧!
1. 安装运行环境
a. 下载emacs,解压即可。
b. 下载slime,解压即可
c. 下载sbcl,安装
d. 配置emacs
首先需要确定emacs会加载哪里的.emacs配置文件(即emacs的HOME目录为什么),可以通过改注册表(新添注册表项HKEY_CURRENT_USER\Software\GNU\Emacs(新建一个GNU项,然后在GNU项下新建一个子项Emacs),新增一个项HOME,设置其字符串值为emacs解压后的目录)
在emacs解压后的目录中,新建一个.emacs文件,添加如下几行:
;for lisp mode
(add-to-list 'load-path "D:\\slime\\") ; 注:在windows下路径分隔符为\\而不是\,否则会被解释为 D:slime, 或者改成另外一种写法 D:/slime
(setq inferior-lisp-program "D:\\SteelBankCommonLisp\\sbcl.exe") ;注:如果此处路径有空格,在M-x slime时会出现问题:apply: Spawning child process: invalid argument
;(setq inferior-lisp-program "D:\\clisp-2.49\\clisp.exe")
(require 'slime-autoloads) ;注意这里加载的是 slime-autoloads,而不是 slime,要不然C-c C-c等很多功能都没有
(slime-setup '(slime-fancy))
;(slime-setup)
2. 编译运行
如果要进入用户交互界面,输入 M-x slime即可
如果要编译lisp文件里的函数:a. 只编译某个函数,可以将光标放在该函数上,然后按C-c C-c
The easiest is to type C-c C-c with the cursor anywhere in or immediately after the DEFUN form, which runs the command slime-compile-defun, which in turn sends the definition to Lisp to be evaluated and compiled.
b. C-c C-c只能编译单个函数,如果文件内一些函数有关联,则这种方式就不好用了,此时可以编译整个文件
(load “lisp_file”)
c. load 某个文件后,如果又修改了该文件中的某个函数,则可以再用C-c C-c编译该函数而不需要重新load该文件
posted @
2010-10-01 22:03 hex108 阅读(8079) |
评论 (4) |
编辑 收藏
一个内存地址存着一个对应的值,这是比较容易理解的。
如果程序员必须清楚地知道某块内存存着什么内容和某个内容存在哪个内存地址里了,那他们的负担可想而知。
汇编语法对“一个内存地址存着一个对应的数”,作了简单的“抽象”:
把内存地址用变量名代替了,对内存地址的取值和赋值方式不变。
c语言对此进行了进一步的抽象:变量 <==> (一个内存地址,对应的值)(这里忽略类型等信息)。
把C语言中的基本类型(int,long,float等),指针,数组等还原为(一个内存地址,对应的值)后,就能更清淅地理解它们了。
内存就相当于(addr,val)的大hash表,c语句的语义基本就是改变hash值。
为了下文的方便,特定义如下语义(遵循C的标准语义):
var <==> (addr, val) (var为一个变量名,addr为var在内存中的首地址,val为var 的值)
&var <==> addr
var <==> var作为左值出现(即等式左边)时,var等价于 addr;
var作为右值出现(即等式左边)时,var等价于 val;
*var <==> val
注:符号"<==>" 右边出的等式 x = y(x是一个内存地址,y是一个值); 表示将内存地址为x的内容置为值y,如addr = 3表示置内存addr里的值为3
现在利用上面的语义解释一下这些例子:
int i = 3;
假设 i的内存地址为 0x8049320 ,那么这句话的语义是0x8049320 = 3,经过i = 3后,i为(0x8049320,3)
int b = i;
假设 b的内存地址为 0x8049324 ,那么这句话的语义是0x8049324 = i对应的val = 3,此时b为(0x8049324,3)
int *p = &b
指针p也是一个变量,int **p,int *p[8],在这些申明中p都只是一个指针变量,它和其他的变量的不同之处在于它的大小是定的,它的类型信息只是编译器用来进行类型检查和其他一些作用的(如果没有类型检查,你可以用任何的方式对一个变量进行操作如int i; ****i = 3)。假设p的地址为0x8049328,则根据p = &b的语义p.addr = b.addr,p为(0x8049328,0x8049324)
*p = 5;
语义为 0x8049324 = 5,此时只改变了内存地址为0x8049324的值,即改变了b的值(0x8049324,5),而p的值并未改变
int **q = &p; //如果写为int **q = &&i; gcc编译不通过
假设q的内存地址为0x8049330,语义为 0x8049330 = addr(p) = 0x8049328;所以q为(0x8049330, 0x8049328)
(int **q = &&i, 要是编译过了则q应该表示为(0x8049330, x),内存地址为x的地方表示为(x,0x8049320),那么地址x为多少呢? )
**q = 6
语义为 val(val(q)) = val(0x8049328) = 0x8049324 = 6,将内存地址为0x8049324的内容置为6,即将b的值置为6,b为(0x8049324,6)
对于结构,这些语义也适用,因为结构里的成员也是有对应地址的,也能表示为(addr,val)的形式。
对“一个内存地址存着一个对应的值”的抽象程度越高,越不用关心底层,如java。
Haskell已经没有副作用之说了,更不用关心这些了。
就这些。
posted @
2010-08-21 23:20 hex108 阅读(6032) |
评论 (7) |
编辑 收藏有作者之一Dave Thomas在敏捷2009大会上关于此书的演讲(http://www.infoq.com/cn/presentations/dt-pragmatic-programmer)
这本书的成书方式很有意思。作者非常喜欢program,以至于将这本书的写作当成了软件工程,全书用plain text写成,以soruce code(应 该是他们自己发明的领域语言DSL~)的方式组织而成,用他们自己写成的工具build一下后就成了此书,相信他们也以某种版本管理工具对此进行了管理(方便查看版本之间的变化等),并对书中的code进行了单元测试。
想像一下他们怎么写书的(借用HTML的格式猜想一下):
<Title>程序员修炼之道</Title>
<Body>
shell游戏
<Code>/home/Dave/game.sh</Code>
</Body>
Test时会自动测试书中的程序,如:game.sh;Build之后本书便完成了(书中的code文件会自动读入)。
这真是一个很成功的“项目”:
*
Automate Everything.
* 如果需要,则设计自己的小语言
Perl有一个作解释器的包
http://search.cpan.org/~dconway/Parse-RecDescent-1.965001/lib/Parse/RecDescent.pm * Fix Broken Windows
--Fix small thing,Then big thing will not happen.
*
Don't repeat yourself(DRY)
-- code duplication
解决方法: 做成函数,模块,类;采用code generators;采用元程序设计(The art of metaprogramming:
http://www.ibm.com /developerworks/linux/library/l-metaprog1.html);采用设计模式(作者觉得采用模式有可能把问题弄复杂);convertions;metaphors;
-- Project Duplication
Fix by producing procduts; Fix with data-driven designs.
* Do one thing better.
简单,低耦合。
* Do Nothing Twice.
* 代码之前,测试先行。
* 选择好的编码工具能有效地提高效率,避免编码中的小错误。
posted @
2010-08-13 20:34 hex108 阅读(383) |
评论 (0) |
编辑 收藏,有一些觉得比较有用的观点,再加些自己的所看到的所学到的。
1. 只在学习区学习
不要对未知的事物感到本能性的恐惧,相信自己能行的。
“心理学家把人的知识和技能分为层层嵌套的三个圆形区域:最内一层是“舒适区”,是我们已经熟练掌握的各种技能;最外一层是“恐慌区”,是我们暂时无法学会
的技能,二者中间则是“学习区”。只有在学习区里面练习,一个人才可能进步。有效的练习任务必须精确的在受训者的“学习区”内进行,具有高度的针对性。在
很多情况下这要求必须要有一个好的老师或者教练,从旁观者的角度更能发现我们最需要改进的地方。”
2. 学到的东西只有
多用,多实践才能化为己用。
纸上得来终觉浅。
3. 多写下自己的所得。
写下的东西可能比在大脑中记下的更有条理,在写的过程中可能会触发新的思路,且有助于理清思路 (这就是为什么一个问题在自言语中为什么有时候会出现答案自己跑出来的情况)所以要多写。
最近发现Vimwiki是个好东西。
4. 优秀是一种习惯。
好习惯的养成很重要(eg:
今日事今日毕就是很重要的)
5. 多看经典之作,不要把时间浪费在无用的东西上。
6. 坚持是最重要的,这样才会有柳暗花明的一天
。
7. 有什么想做的事就大胆去做吧,谁保证以后还会有机会?
借用《明朝那些事》里的一句话“按照自己的方式去活才是最大的成功”。
posted @
2010-08-10 20:37 hex108 阅读(567) |
评论 (0) |
编辑 收藏 计算机原本就该从事简单重复的工作。只要把任务指派给它们,它们就可以一遍又一遍毫不走样地重复执行,而且速度很快。但却经常看见一种奇怪的现象:人们在计算机上手工做一些简单重复的工作,计算机则在大半夜里扎堆闲聊取笑这些可怜的用户。
我们应该利用作为程序员的优势,看到普通用户无法看到的东西,培养larry所说的“懒惰,急躁和傲慢”让计算机高效地为我们工作:命令行是如此地高效,脚本是如此地方便,衔接两个小工具能达到如此神奇的效果。。。
古代哲人1. 亚里斯多德的“事物本质性质和附属性质”理论:致力本质复杂性,去除附属复杂性。你现在想解决问题A,在解决A的问题中遇到了问题B,接着你去解决问题B,戏剧性的是你遇到了很多接二连三的问题C,D,E,或者在很多年后,程序才出现问题C,D,E,可是你的最初问题是A,不是吗?B,C,D等等都是附属性质,当这些附属性质越来越多,越来越复杂的时候,也是开始思考另一个解决A的办法的时候了。(如果作为学习,可以试着去解决那些附属性质)
2. 笛米特法则:任何一个对象或者方法,它应该只能调用下列对象:该对象本身,作为参数传递进来的对象,在方法内创建的对象。这么做的主要目的是信息隐藏,同时使类的耦合更加松散。
3. “古老”的软件传说。了解历史才能更好地创造历史。读读那些“古老”的“宝典”(如《程序员修炼之道》《人月神话》《Smalltalk Best Practice Patterns》),会学到很多有用的东西,或许你会发出一生惊叹。“当你的老板要求你使用一个低质量的代码库时,不需要在崩溃中咬牙切齿,告诉他:你正“站在侏儒的肩膀”上的陷阱中,然后他就会明白不仅仅只有你才觉得那是个坏主意。”
拥抱多语言编程 “每个语言都有自己擅长的地方”(我的想法)。比如perl特别适合文本处理,用来处理网页也很好(毕竟有些从服务器上返回的数据就是用perl返回的,所以用perl也会比较合适)。
计算机语言就像鲨鱼,要是保持静止就会死。
Java的创造都们实际上创造了两样东西:Java语言和Java平台。后者就是我们摆脱历史包袱的途径(Java语言的特性包含了一些它本该可以忽略的东西,如Java程序初始化的顺序和从0开始的数组)。读到本文我才开始理解平台的深刻意义。
举两个例子(Groovy和Jaskell)说明。
Groovy是一种开源的编程语言,它给Java带来了动态语言的语法和功能,它会生成Java字节码,因此可以在Java平台上运行。在Java之后十多年里浮现出来的各种语言很大程序上影响着Groovy的语法:Groovy支持装饰,较松散的类型系统,“理解”迭代的集合,以及很多现代编程语言的改进特性。而且它可以编译成纯正的Java字节码。用Groovy写成的代码简洁且并不比用Java写的代码效率低多少,而且能充分借用Java平台的优势。
Jaskell是运行在Java平台上的Haskell版本。Jaskell拥有函数式程序设计语言的优势:函数不改变外界的状态,纯粹的函数式语言压根没有“变量”概念;函数式语言对多线程的支持比命令式语言要强得多,用函数式语言更容易写出强壮的线程安全的代码,对并发支持也比较好(我想这是Erlang流行的原因)。同时Jaskell也能借用Java平台的优势。
Java平台借用这些多语言特性,一定会走得更好,走得更远。不过,在带来好处的同时,也带来了一个问题:多语言应用程序更难高度,解决这个问题最简单的办法也跟现在一样:靠严格的单元测试来避免在调试器上浪费时间。
多语言开发风格会把我们带向领域特定语言(Domain-specific Language,DSL)。我们会以一些专门的语言为基础,创造出非常有针对性的,非常专注某一问题域的DSL。抱定一种通用语言不放的年代就快结束了,我们正在进入一个专业细分的新时代。大学时代的Haskell教材还在书架顶上蒙尘吗?该给它掸掸灰了。
ps: 我们也可以以C++为基础,来创造一种DSL,思考。
链接: 卓有成效的程序员
posted @
2010-07-10 12:40 hex108 阅读(950) |
评论 (4) |
编辑 收藏"A useful way to get some insight into what linkers and loaders do is to look at their part in the development of computer programming systems."
一. 目标1. 理解Linker和Loader的大致工作过程。
2. 写一个关于elf的小loader。
3. 会感染ELF和PE文件。
二. 有用的链接1. 本书《Linkers and Loaders
》的网址:
http://linker.iecc.com/
posted @
2010-07-06 20:51 hex108 阅读(445) |
评论 (0) |
编辑 收藏
一.
简介 该正则表达式暂时能识别 *,|,(,)等特殊符号,如(a|b)*abc。不过扩展到其他符号(如?)也相对比较容易,修改NFA中的构建规则即可。
二.
引擎的构建 该正则表达式引擎的构建以《Compilers Principles,Techniques & Tools》3.7节为依据,暂时只能识别*,|,(,)这几个特殊的字符,其工作过程为:构建NFA -> 根据NFA构建DFA -> 用DFA匹配。
1. 构建NFA
该NFA的构建以2条基本规则和3条组合规则为基础,采用归纳的思想构建而成。
1)2条基本的规则是:
a. 以一个空值ε构建一个NFA
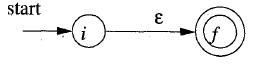
b. 以一个字符a构建一个NFA
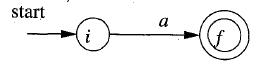
2) 3条组合规则是:
a. r = s | t (其中s和t都是NFA)
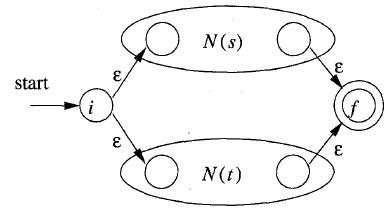
b. r = s t(其中s和t都是NFA)

c. r = s *(其中s为NFA)
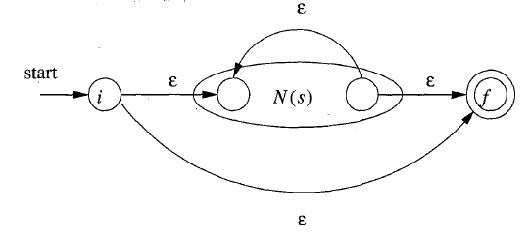
3) 如果需要识别如”?”等特殊符号,则可再加一些组合规则。
在具体的程序中,可以以下面的BNF为结构来实现。(具体见源程序regexp.cpp)
r -> r '|' s | r
s -> s t | s
t -> a '*' | a
a -> token | '(' r ')' | ε
2. 构建DFA
主要是求ε闭包的过程,从一个集合的ε闭包转移到一个集合的ε闭包。
以a*c为例,其NFA图如下所示(用dot画的)
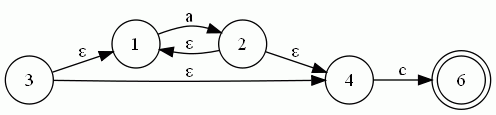
为例:
起始结点3的ε闭包集为 A = {3,1,4}
A遇上字母a的转移为MOV(A,a) = { 2 },其ε闭包集为B = { 2,1,4 }
A遇上字母c的转移为MOV(A,c) = { 6 },其ε闭包集为B = { 6 }
同理可求出其他转移集合,最后得到的DFA如下所示:
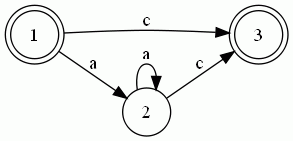
3. 匹配
每匹配成功一个字符则DFA移动到下个相应的结点。
三.
改进1. 如龙书中所说,有时候模拟NFA而不是直接构建DFA可能达到更好的效果。
2. 每次匹配不成功都需要回溯,这个地方也可以借鉴KMP算法(不过KMP对此好像有点不适用)
3. 其他改进方法可以看看《柔性字符串匹配》和龙书《Compilers Principles,Techniques & Tools》3.7节。
四. 代码下载
svn checkout http://regexp.googlecode.com/svn/trunk/ regexp-read-only
或
regexp.rar
posted @
2010-06-17 20:50 hex108 阅读(774) |
评论 (2) |
编辑 收藏