继续未完成的内容,声明
本文仅用于学习研究,不提供解压工具和实际代码。
由于时间仓促,剑3资源格式分析(仅用于学习和技术研究)(一)
大部分只是贴出了分析的结果,并没有详细的分析过程,比如:如何知道那是一个pak文件处理对象,
如何根据虚表偏移获取实际函数地址等等,这就需要读者对c++对象在内存中的layout有一定基础。
开始正文了~~,先整理下前面的分析结果:
1、剑3是通过package.ini 来管理pak文件的,最多可配置key从 0-32(0x20)的32个文件。
2、每个pak文件都用一个独立对象来管理,所有的pak对象指针存储在一个数组里(这个后面会用到)。
3、pak文件格式:[pak标记(Uint32)] + [文件数目(Uint32)]+[索引数据偏移(Uint32)]+未知内容。另外,每个文件的索引数据是16个字节。
一、路径名哈希
剑3的pak的内部文件是通过hash值来查找的,这样有利于加快查询速度。这就需要有一个函数通过传入 路径名返回hash值。
这个函数居然是导出的。。。g_FileNameHash
这个函数代码比较少,可以逆向出来用C重写,也可以直接使用引擎函数(LoadLibrary,GetProceAddress来使用)。
熟悉剑侠系列的朋友会发现,这个函数从新剑侠情缘(可能历史更久)开始就没有变过(确实没必要变),具体细节就不逐个分析了,我是写了一个单独的命令行工具
来测试的。
二、查询过程
查询函数在sub_10010E00
里,也就是(0x10010E00)的位置,我是通过简单分析g_IsFileExist 得知这个函数功能的。下面
来分析这个函数过程:
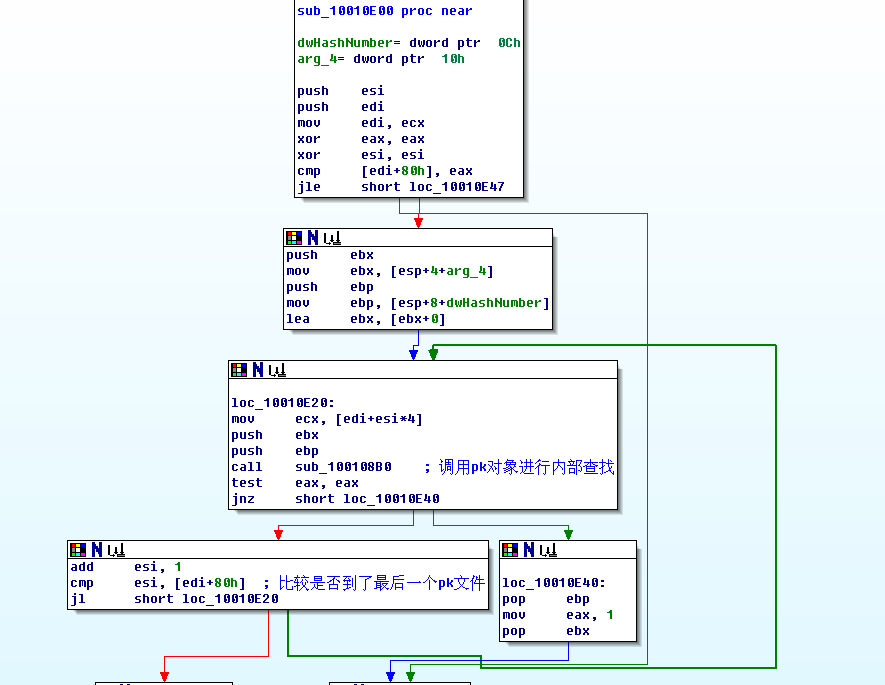
从前文可知,pak文件对象是存储在一个数组的这个数组是类似 KPakFile* m_szPakFile[0x21];
前面0x20个存储的都是KPakFile对象指针,最后一个存储的是数组长度。
这个搜索结构比较简单,就是遍历所有的KPakFile对象,逐个查询,找到了就返回。想知道具体怎么查询的吗,
接下来要看sub_100108B0了。
这个函数稍微有点长,分几个部分来分析吧:
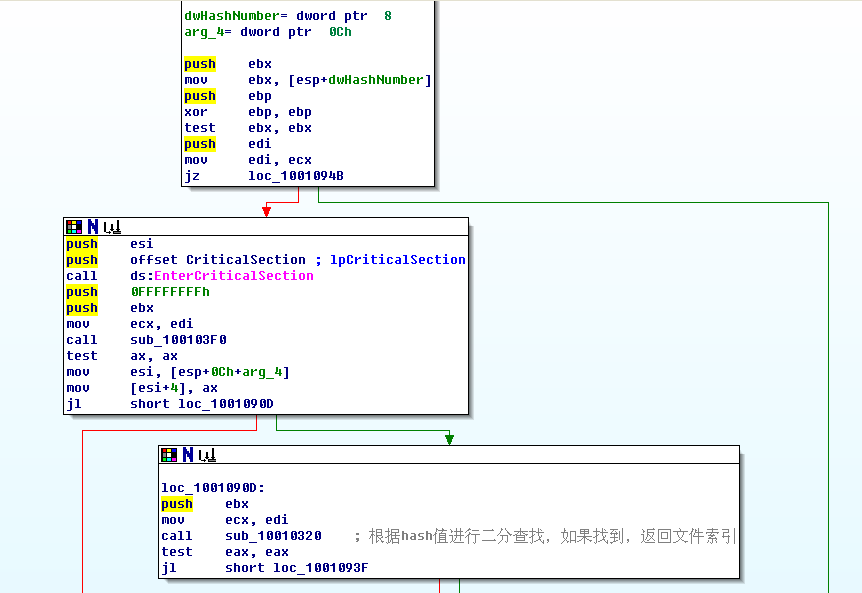
首先,验证下Hash值是否是0,如果是0,肯定是错了:)
然后接着开始根据这个hash值进行查找了,经过分析,我发现这个函数其实是一个二分查找,代码贴出来如下 sub_10010320
:

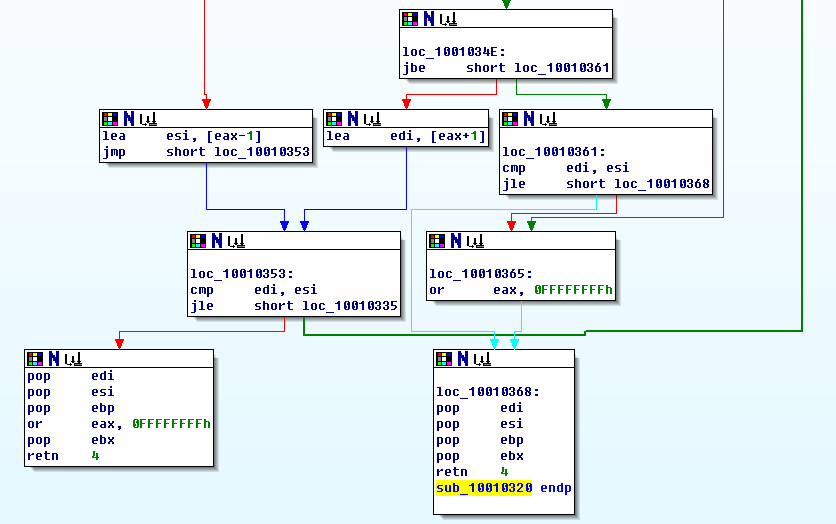
从上面的代码还是比较容易可以知道,每个文件的16个索引数据中,前4个字节是hash值,这个函数返回的是这个文件是pak包的第几个。
接着前面的sub_100108B0
来看吧
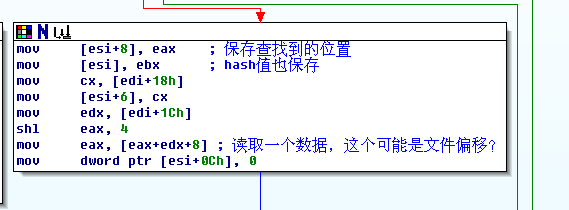
这一段是保存查询到的数据到对象里。分析到这里,我只知道16个索引数据前4个字节是hash值,那么剩下的12个字节呢,
剩下的数据基本可以确定是:文件偏移、文件长度。我是个懒人,接下来的分析我是通过在fseek、fread下断点来得到的,为什么不是在SetFilePointer和ReadFile呢,
这是根据前面的分析得到的,因为pak文件管理对象使用的是C标准库函数。
根据fread和fseek的结果,可以得到如下结果:
索引数据构成是:
[哈希数值(Uint32)] + [文件偏移(Uint32)]+[未知数据(Uint32)] + 2(文件长度)+2(未知数据)。
剩下的,就是看看单独内部文件的解压方式了,
在fread的缓冲区上设置内存断点,就可以找到解压函数了:
sub_10018020
这个函数不算太长,一开始我也想逆向成C语言,后来看到如此多的分支就放弃了,转而用了一个偷懒的办法解决了:
从汇编代码可知这个函数的原型:
typedef int (*PUNPACK_FUN)(void* psrcData, int nSrcLen, void* pDstData, int* pDstLen);
直接加载剑3的dll,设置函数地址:
PUNPACK_FUN pEngineUnpack = (PUNPACK_FUN)((unsigned int)hEngineModule + 0x18020);
hEngineModule
是引擎dll的基址,大家看到了吧,dll的函数即使不导出,我们也是可以调用的:)
三、尾声
到这里,已经可以写出一个pak文件的解压包了,但是,我们还是没有还原真实的文件名,
下面是我解压的script.pak的文件的部分内容:

终于看到大侠们的签名了。当然,对着一堆hash值为名字的文件,阅读起来确实很困难,
那么有办法还原真实的文件名吗,办法还是有一些的,可以通过各种办法改写g_OpenFileInPak记录参数名,来获取游戏中用到的pak内部文件名,相信这难不倒各位了。
posted @
2010-07-16 20:47 feixuwu 阅读(4921) |
评论 (11) |
编辑 收藏
这几天在玩剑三,突然兴趣来了,想要分析剑3的资源打包格式。在资源分析和逆向方面原来偶尔也干过,
不过总体来说还是处于菜鸟阶段,这篇文章希望和其他有兴趣的兄弟分享下这几天的经历,仅仅作为技术研究。
一、安全保护
一般来说,很少有游戏的资源格式可以直接通过分析资源文件本身得到答案,大部分难免要静态逆向、动态调试。
无论是静态逆向还是动态调试,首先需要知道当前exe和dll的保护情况,用peid查看,发现只有gameupdater.exe 用upx加壳了。不太明白金山为什么对客户端没有加壳。
其实我并不关心gameupdater.exe 是否加壳,毕竟要动态分析的目标是JX3Client.exe
,要动态调试JX3Client.exe,首先要解决启动参数问题。
二、启动参数
如果直接启动JX3Client.exe,JX3Client.exe会直接退出,并启动gameuodater.exe,然后通过gameupdater.exe启动JX3Client.exe。
这种启动方式会影响动态调试,所以首先我需要找出JX3Client.exe的启动参数。打开IDA逆向,转到启动处,汇编代码如下:


start proc near
call ___security_init_cookie
jmp ___tmainCRTStartup
start endp
这是一个典型的VC程序入口,在___tmainCRTStartup
里,crt会初始化全局变量、静态变量,然后进入main,我们需要做的是直接找到main,
跟进去,会发现IDA已经帮我们找到WinMain了,直接跟进去,
关键代码在WinMain的入口处:
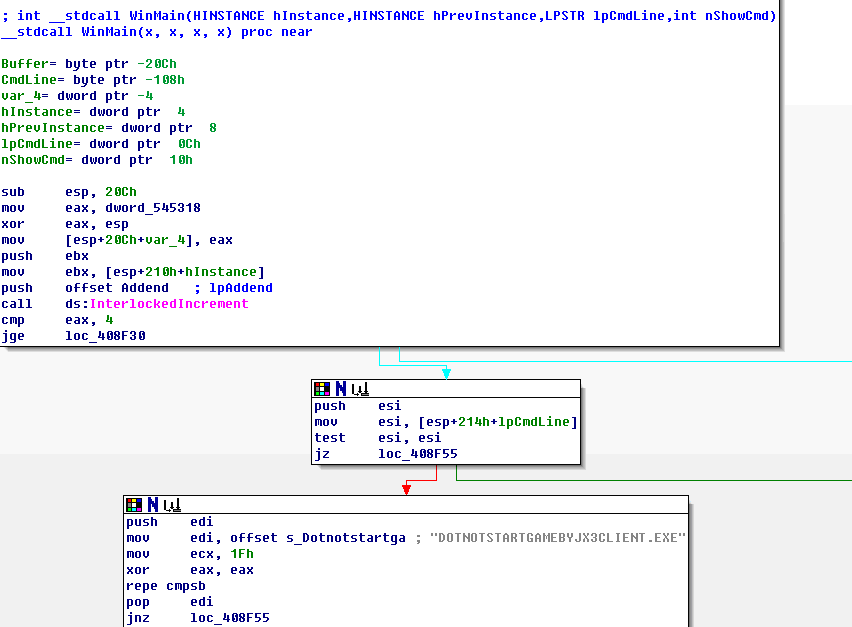
从这个代码片段可以知道,WinMain开始就比较了命令行参数是否是"DOTNOTSTARTGAMEBYJX3CLIENT.EXE
",如果不是,
则转到启动更新程序了。这个好办,我们写一个run.bat,内容只有一行:
JX3Client.exe DOTNOTSTARTGAMEBYJX3CLIENT.EXE
运行,果然,直接看到加载界面了。
三、PAK文件管理
在剑3里,PAK目录下有很多PAK文件,剑3是通过package.ini 来加载和管理pak内部文件的。
这个文件内容如下:
[SO3Client]
10=data_5.pak
1=ui.pak
0=update_1.pak
3=maps.pak
2=settings.pak
5=scripts.pak
4=represent.pak
7=data_2.pak
6=data_1.pak
9=data_4.pak
Path=.\pak
8=data_3.pak
基本上PAK目录下所有的PAK文件都列出来了,其实剑3的资源文件打包方式基本上和新剑侠情缘类似(细节还是有比较大的差别)。
打开ollyDbg,带参数启动JX3Client.exe,在CreateFile设置断点,可以发现,package.ini
的读取和处理是在
Engine_Lua5.dll
的g_LoadPackageFiles
函数,熟悉新剑侠情缘资源管理方式的同学大概会猜到这个函数是做什么的,先看看函数内容吧,这个函数比较长
只能逐步的分析了,首先是打开ini文件
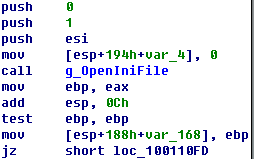
使用g_OpenIniFile打开前面提到的ini文件,如果打开失败,自然直接返回了。
打开成功后,循环读取ini配置的文件,读取的section是SO3Client 读取的key是0到0x20。
loc_1001119A: ; int
push 0Ah
lea ecx, [esp+1A0h+var_178]
push ecx ; char *
push ebx ; int
call ds:_itoa ; 这是根据数字生成key的代码
mov edx, [ebp+0]
mov edx, [edx+24h]
add esp, 0Ch
push 40h
lea eax, [esp+1A0h+var_168]
push eax
mov eax, [esp+1A4h+var_184]
push offset unk_10035B8C
lea ecx, [esp+1A8h+var_178]
push ecx
push eax
mov ecx, ebp
call edx ; 读取INI内容 readString(section, key)
test eax, eax
jz loc_1001127A
这段是通过readString("SO3Client", key)来获取pak文件名, key就是"0"~"32"的字符串,也就是最多能配置32个Pak文件。
获得了pak文件名后,下面就是打开和保存pak文件的索引数据了。

后面的注释是我分析的时候加上的,IDA这个功能不错!
首先new一个0x20字节的空间用来存储pak对象(我自己命名的类),接着调用构造函数,创建pak对象。
创建对象后,要用这个Pak对象打开对应的pak文件了,这是我们下面的代码:
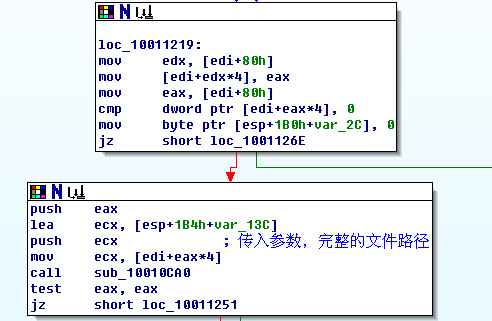
首先通过
mov [edi+edx*4], eax
将对象保存,然后,调用这个类的成员函数打开pak文件,具体代码在sub_10010ca0。
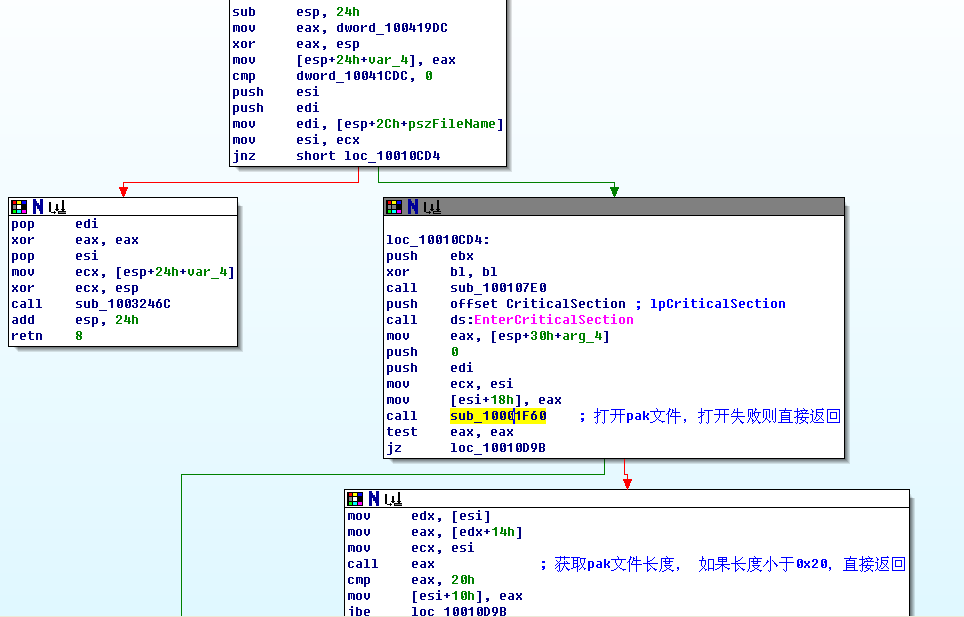
这段代码的意思很明白了,打开文件,读取0x20的文件头,
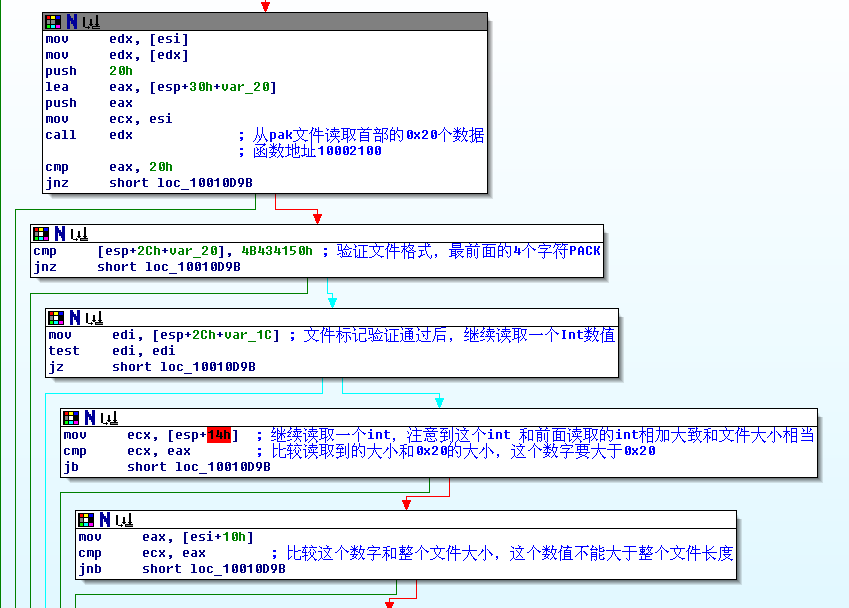
这里做的是验证文件格式,和一些必要的验证。

这段是读取pak内部文件数目,读取索引数据,以备后面查询使用。
到此为止,所有pak文件的管理对象都已经加载和设置完毕了。
以上内容看起来很顺理成章,但是实际上凝聚了无数的失败和重试。
后面是pak内部文件的查找和读取了。
剩下的内容明天贴了~~~
posted @
2010-07-15 21:07 feixuwu 阅读(5365) |
评论 (10) |
编辑 收藏
最近有朋友在面试的时候被问了select 和epoll效率差的原因,和一般人一样,大部分都会回答select是轮询、epoll是触发式的,所以效率高。这个答案听上去很完美,大致也说出了二者的主要区别。
今天闲来无事,翻看了下内核代码,结合内核代码和大家分享下我的观点。
一、连接数
我本人也曾经在项目中用过select和epoll,对于select,感触最深的是linux下select最大数目限制(windows 下似乎没有限制),每个进程的select最多能处理FD_SETSIZE个FD(文件句柄),
如果要处理超过1024个句柄,只能采用多进程了。
常见的使用slect的多进程模型是这样的: 一个进程专门accept,成功后将fd通过unix socket传递给子进程处理,父进程可以根据子进程负载分派。曾经用过1个父进程+4个子进程 承载了超过4000个的负载。
这种模型在我们当时的业务运行的非常好。epoll在连接数方面没有限制,当然可能需要用户调用API重现设置进程的资源限制。
二、IO差别
1、select的实现
这段可以结合linux内核代码描述了,我使用的是2.6.28,其他2.6的代码应该差不多吧。
先看看select:
select系统调用的代码在fs/Select.c下,
asmlinkage long sys_select(int n, fd_set __user *inp, fd_set __user *outp,
fd_set __user *exp, struct timeval __user *tvp)
{
struct timespec end_time, *to = NULL;
struct timeval tv;
int ret;
if (tvp) {
if (copy_from_user(&tv, tvp, sizeof(tv)))
return -EFAULT;
to = &end_time;
if (poll_select_set_timeout(to,
tv.tv_sec + (tv.tv_usec / USEC_PER_SEC),
(tv.tv_usec % USEC_PER_SEC) * NSEC_PER_USEC))
return -EINVAL;
}
ret = core_sys_select(n, inp, outp, exp, to);
ret = poll_select_copy_remaining(&end_time, tvp, 1, ret);
return ret;
}
前面是从用户控件拷贝各个fd_set到内核空间,接下来的具体工作在core_sys_select中,
core_sys_select->do_select,真正的核心内容在do_select里:
int do_select(int n, fd_set_bits *fds, struct timespec *end_time)
{
ktime_t expire, *to = NULL;
struct poll_wqueues table;
poll_table *wait;
int retval, i, timed_out = 0;
unsigned long slack = 0;
rcu_read_lock();
retval = max_select_fd(n, fds);
rcu_read_unlock();
if (retval < 0)
return retval;
n = retval;
poll_initwait(&table);
wait = &table.pt;
if (end_time && !end_time->tv_sec && !end_time->tv_nsec) {
wait = NULL;
timed_out = 1;
}
if (end_time && !timed_out)
slack = estimate_accuracy(end_time);
retval = 0;
for (;;) {
unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp;
set_current_state(TASK_INTERRUPTIBLE);
inp = fds->in; outp = fds->out; exp = fds->ex;
rinp = fds->res_in; routp = fds->res_out; rexp = fds->res_ex;
for (i = 0; i < n; ++rinp, ++routp, ++rexp) {
unsigned long in, out, ex, all_bits, bit = 1, mask, j;
unsigned long res_in = 0, res_out = 0, res_ex = 0;
const struct file_operations *f_op = NULL;
struct file *file = NULL;
in = *inp++; out = *outp++; ex = *exp++;
all_bits = in | out | ex;
if (all_bits == 0) {
i += __NFDBITS;
continue;
}
for (j = 0; j < __NFDBITS; ++j, ++i, bit <<= 1) {
int fput_needed;
if (i >= n)
break;
if (!(bit & all_bits))
continue;
file = fget_light(i, &fput_needed);
if (file) {
f_op = file->f_op;
mask = DEFAULT_POLLMASK;
if (f_op && f_op->poll)
mask = (*f_op->poll)(file, retval ? NULL : wait);
fput_light(file, fput_needed);
if ((mask & POLLIN_SET) && (in & bit)) {
res_in |= bit;
retval++;
}
if ((mask & POLLOUT_SET) && (out & bit)) {
res_out |= bit;
retval++;
}
if ((mask & POLLEX_SET) && (ex & bit)) {
res_ex |= bit;
retval++;
}
}
}
if (res_in)
*rinp = res_in;
if (res_out)
*routp = res_out;
if (res_ex)
*rexp = res_ex;
cond_resched();
}
wait = NULL;
if (retval || timed_out || signal_pending(current))
break;
if (table.error) {
retval = table.error;
break;
}
/*
* If this is the first loop and we have a timeout
* given, then we convert to ktime_t and set the to
* pointer to the expiry value.
*/
if (end_time && !to) {
expire = timespec_to_ktime(*end_time);
to = &expire;
}
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1;
}
__set_current_state(TASK_RUNNING);
poll_freewait(&table);
return retval;
}
上面的代码很多,其实真正关键的代码是这一句:
mask = (*f_op->poll)(file, retval ? NULL : wait);
这个是调用文件系统的 poll函数,不同的文件系统poll函数自然不同,由于我们这里关注的是tcp连接,而socketfs的注册在 net/Socket.c里。
register_filesystem(&sock_fs_type);
socket文件系统的函数也是在net/Socket.c里:
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_sock_ioctl,
#endif
.mmap = sock_mmap,
.open = sock_no_open, /* special open code to disallow open via /proc */
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
从sock_poll跟随下去,
最后可以到 net/ipv4/tcp.c的
unsigned int tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
这个是最终的查询函数,
也就是说select 的核心功能是调用tcp文件系统的poll函数,不停的查询,如果没有想要的数据,主动执行一次调度(防止一直占用cpu),直到有一个连接有想要的消息为止。
从这里可以看出select的执行方式基本就是不同的调用poll,直到有需要的消息为止,如果select 处理的socket很多,这其实对整个机器的性能也是一个消耗。
2、epoll的实现
epoll的实现代码在 fs/EventPoll.c下,
由于epoll涉及到几个系统调用,这里不逐个分析了,仅仅分析几个关键点,
第一个关键点在
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
这是在我们调用sys_epoll_ctl 添加一个被管理socket的时候调用的函数,关键的几行如下:
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* Attach the item to the poll hooks and get current event bits.
* We can safely use the file* here because its usage count has
* been increased by the caller of this function. Note that after
* this operation completes, the poll callback can start hitting
* the new item.
*/
revents = tfile->f_op->poll(tfile, &epq.pt);
这里也是调用文件系统的poll函数,不过这次初始化了一个结构,这个结构会带有一个poll函数的callback函数:ep_ptable_queue_proc,
在调用poll函数的时候,会执行这个callback,这个callback的功能就是将当前进程添加到 socket的等待进程上。
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
注意到参数 whead
实际上是 sk->sleep,其实就是将当前进程添加到sk的等待队列里,当该socket收到数据或者其他事件触发时,会调用
sock_def_readable
或者sock_def_write_space
通知函数来唤醒等待进程,这2个函数都是在socket创建的时候填充在sk结构里的。
从前面的分析来看,epoll确实是比select聪明的多、轻松的多,不用再苦哈哈的去轮询了。
posted @
2010-07-10 18:40 feixuwu 阅读(10340) |
评论 (3) |
编辑 收藏
昨天一个同事一大早在群里推荐了一个google project上的开源内存分配器(
http://code.google.com/p/google-perftools/),据说google的很多产品都用到了这个内存分配库,而且经他测试,我们的游戏客户端集成了这个最新内存分配器后,FPS足足提高了将近10帧左右,这可是个了不起的提升,要知道3D组的兄弟忙了几周也没见这么大的性能提升。
如果我们自己本身用的crt提供的内存分配器,这个提升也算不得什么。问题是我们内部系统是有一个小内存管理器的,一般来说小内存分配的算法都大同小异,现成的实现也很多,比如linux内核的slab、SGI STL的分配器、ogre自带的内存分配器,我们自己的内存分配器也和前面列举的实现差不多。让我们来看看这个项目有什么特别的吧。
一、使用方法
打开主页,由于公司网络禁止SVN从外部更新,所以只能下载了打包的源代码。解压后,看到有个doc目录,进去,打开使用文档,发现使用方法极为简单:
To use TCMalloc, just link TCMalloc into your application via the
"-ltcmalloc" linker flag.再看算法,也没什么特别的,还是和slab以及SGI STL分配器类似的算法。
unix环境居然只要链接这个tcmalloc库就可以了!,太方便了,不过我手头没有linux环境,文档上也没提到windows环境怎么使用,
打开源代码包,有个vs2003解决方案,打开,随便挑选一个测试项目,查看项目属性,发现仅仅有2点不同:
1、链接器命令行里多了
"..\..\release\libtcmalloc_minimal.lib",就是链接的时候依赖了这个内存优化库。
2、链接器->输入->强制符号引用 多了 __tcmalloc。
这样就可以正确的使用tcmalloc库了,测试了下,测试项目运行OK!
二、如何替换CRT的malloc
从前面的描述可知,项目强制引用了__tcmalloc, 搜索了测试代码,没发现用到_tcmalloc相关的函数和变量,这个选项应该是为了防止dll被优化掉(因为代码里没有什么地方用到这个dll的符号)。
初看起来,链接这个库后,不会影响任何现有代码:我们没有引用这个Lib库的头文件,也没有使用过这个dll的导出函数。那么这个dll是怎么优化应用程序性能的呢?
实际调试,果然发现问题了,看看如下代码
void* pData = malloc(100);
00401085 6A 64 push 64h
00401087 FF 15 A4 20 40 00 call dword ptr [__imp__malloc (4020A4h)]
跟踪 call malloc这句,step进去,发现是
78134D09 E9 D2 37 ED 97 jmp `anonymous namespace'::LibcInfoWithPatchFunctions<8>::Perftools_malloc (100084E0h)
果然,从这里开始,就跳转到libtcmalloc提供的Perftools_malloc了。
原来是通过API挂钩来实现无缝替换系统自带的malloc等crt函数的,而且还是通过大家公认的不推荐的改写函数入口指令来实现的,一般只有在游戏外挂和金山词霸之类的软件才会用到这样的挂钩技术,
而且金山词霸经常需要更新补丁解决不同系统兼容问题。
三、性能差别原因
如前面所述,tcmalloc确实用了很hacker的办法来实现无缝的替换系统自带的内存分配函数(本人在使用这类技术通常是用来干坏事的。。。),但是这也不足以解释为什么它的效率比我们自己的好那么多。
回到tcmalloc 的手册,tcmalloc除了使用常规的小内存管理外,对多线程环境做了特殊处理,这和我原来见到的内存分配器大有不同,一般的内存分配器作者都会偷懒,把多线程问题扔给使用者,大多是加
个bool型的模板参数来表示是否是多线程环境,还美其名曰:可定制,末了还得吹嘘下模板的优越性。
tcmalloc是怎么做的呢? 答案是每线程一个ThreadCache,大部分操作系统都会支持thread local storage 就是传说中的TLS,这样就可以实现每线程一个分配器了,
这样,不同线程分配都是在各自的threadCache里分配的。我们的项目的分配器由于是多线程环境的,所以不管三七二十一,全都加锁了,性能自然就低了。
仅仅是如此,还是不足以将tcmalloc和ptmalloc2分个高下,后者也是每个线程都有threadCache的。
关于这个问题,doc里有一段说明,原文贴出来:
ptmalloc2 also reduces lock contention by using per-thread arenas but
there is a big problem with ptmalloc2's use of per-thread arenas. In
ptmalloc2 memory can never move from one arena to another. This can
lead to huge amounts of wasted space.
大意是这样的:ptmalloc2 也是通过tls来降低线程锁,但是ptmalloc2各个线程的内存是独立的,也就是说,第一个线程申请的内存,释放的时候还是必须放到第一个线程池中(不可移动),这样可能导致大量内存浪费。
四、代码细节
1、无缝替换malloc等crt和系统分配函数。
前面提到tcmalloc会无缝的替换掉原有dll中的malloc,这就意味着使用tcmalloc的项目必须是 MD(多线程dll)或者MDd(多线程dll调试)。tcmalloc的dll定义了一个
static TCMallocGuard module_enter_exit_hook;
的静态变量,这个变量会在dll加载的时候先于DllMain运行,在这个类的构造函数,会运行PatchWindowsFunctions来挂钩所有dll的 malloc、free、new等分配函数,这样就达到了替换功能,除此之外,
为了保证系统兼容性,挂钩API的时候还实现了智能分析指令,否则写入第一条Jmp指令的时候可能会破环后续指令的完整性。
2、LibcInfoWithPatchFunctions 和ThreadCache。
LibcInfoWithPatchFunctions模板类包含tcmalloc实现的优化后的malloc等一系列函数。LibcInfoWithPatchFunctions的模板参数在我看来没什么用处,tcmalloc默认可以挂钩
最多10个带有malloc导出函数的库(我想肯定是够用了)。ThreadCache在每个线程都会有一个TLS对象:
__thread ThreadCache* ThreadCache::threadlocal_heap_。
3、可能的问题
设想下这样一个情景:假如有一个dll 在tcmalloc之前加载,并且在分配了内存(使用crt提供的malloc),那么在加载tcmalloc后,tcmalloc会替换所有的free函数,然后,在某个时刻,
在前面的那个dll代码中释放该内存,这岂不是很危险。实际测试发现没有任何问题,关键在这里:
span = Static::pageheap()->GetDescriptor(p);
if (!span) {
// span can be NULL because the pointer passed in is invalid
// (not something returned by malloc or friends), or because the
// pointer was allocated with some other allocator besides
// tcmalloc. The latter can happen if tcmalloc is linked in via
// a dynamic library, but is not listed last on the link line.
// In that case, libraries after it on the link line will
// allocate with libc malloc, but free with tcmalloc's free.
(*invalid_free_fn)(ptr); // Decide how to handle the bad free request
return;
}
tcmalloc会通过span识别这个内存是否自己分配的,如果不是,tcmalloc会调用该dll原始对应函数(这个很重要)释放。这样就解决了这个棘手的问题。
五、其他
其实tcmalloc使用的每个技术点我从前都用过,但是我从来没想过用API挂钩来实现这样一个有趣的内存优化库(即使想过,也是一闪而过就否定了)。
从tcmalloc得到灵感,结合常用的外挂技术,可以很轻松的开发一个独立工具:这个工具可以挂载到指定进程进行内存优化,在我看来,这可能可以作为一个外挂辅助工具来优化那些
内存优化做的很差导致帧速很低的国产游戏。
posted @
2010-07-10 17:32 feixuwu 阅读(10210) |
评论 (14) |
编辑 收藏