几天不写程序手就有点生,整理了一段把图片转成ASCII码的程序。暂时只支持24位真彩色图片,ASCII码可以自行扩充。大体算法就是把整个位图分成8*16的小块,计算小块的灰度值总和,然后匹配一个灰度值接近的字符。具体算法细节可以参考网上资料。
程序源代码可以在
这里下载。
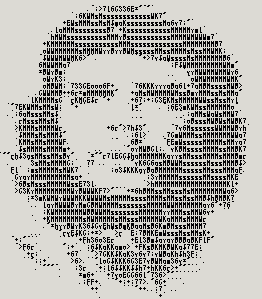
posted @
2008-06-29 18:03 小四 阅读(4031) |
评论 (11) |
编辑 收藏打算做一个开源的矢量绘图软件(类似MS Visio),花了几天把程序框架做了出来,自认比DrawCLI的稍微好一点点。支持基本图形绘制,旋转,缩放,串行化。使用MFC、STL、GDI/GDI+和一点点设计模式。
自知做一个堪用的矢量绘图软件是个非常艰巨的事情,不过还是打算用一些业余时间把这件事情做了,对自己以往掌握的知识,也是一个总结。
编译好的可执行程序程序0.01版本源代码在
这里可以下载
posted @
2008-01-29 18:16 小四 阅读(12379) |
评论 (37) |
编辑 收藏The barrier to change is not too little caring; it is too much complexity.
To turn caring into action, we need to see a problem, see a solution, and see the impact. But complexity blocks all three steps.
If we can really see a problem, which is the first step, we come to the second step: cutting through the complexity to find a solution.
Cutting through complexity to find a solution runs through four predictable stages: determine a goal, find the highest-leverage approach, discover the ideal technology for that approach, and in the meantime, make the smartest application of the technology that you already have — whether it's something sophisticated, like a drug, or something simpler, like a bednet.
The final step – after seeing the problem and finding an approach – is to measure the impact of your work and share your successes and failures so that others learn from your efforts.
But if you want to inspire people to participate, you have to show more than numbers; you have to convey the human impact of the work – so people can feel what saving a life means to the families affected.
posted @
2008-01-15 10:04 小四 阅读(387) |
评论 (0) |
编辑 收藏GDI+的颜色矩阵由一个5*5的float型数组构成,用来对每一个像素的颜色(R,G,B,A)做线性变换,每个像素颜色与矩阵相乘。把一幅彩色图转成灰度图的算法是,假设像素点颜色为(r,g,b),转换成灰度图三个颜色分量是一样的,称作灰阶,灰阶的计算是 r*0.299+g*0.587+b*0.114。我们可以逐个像素转换,也可以使用颜色矩阵。所以彩色图转灰度图的颜色矩阵为
ColorMatrix matrix =
{0.299, 0.299, 0.299, 0, 0,
0.587, 0.587, 0.587, 0, 0,
0.114, 0.114, 0.114, 0, 0,
0, 0, 0, 1, 0,
0, 0, 0, 0, 0}
这样转换后,灰度图的灰阶分布在0~255之间。如果想把一幅彩色图渲染成双色图,定义一个深颜色darker,一个浅颜色lighter,那么灰度图只是一个darker是黑色而lighter是白色的特例。本来分布在0~255的灰阶,这样应该分别分布在(lighter.r~darker.r),(lighter.g~darker.g),(lighter.b~darker.b)。
编写代码如下,使用白色和紫色。
 void CDuotoneDlg::OnButton1()
void CDuotoneDlg::OnButton1()


 {
{
 Bitmap img(L"c:\\test1.jpg");
Bitmap img(L"c:\\test1.jpg");
Graphics graphix(this->GetDC()->m_hDC);
Color darker(0);
Color lighter(8414370);
const float gray_r = 0.299f;
const float gray_g = 0.587f;
const float gray_b = 0.114f;
float offset_r = (float)darker.GetR() / 255;
float offset_g = (float)darker.GetG() / 255;
float offset_b = (float)darker.GetB() / 255;
float r = (float)(lighter.GetR() - darker.GetR()) / 255;
float g = (float)(lighter.GetG() - darker.GetG()) / 255;
float b = (float)(lighter.GetB() - darker.GetB()) / 255;
ImageAttributes imgatt;
ColorMatrix matrix =

 {
{
gray_r*r, gray_r*g, gray_r*b, 0, 0,
gray_g*r, gray_g*g, gray_g*b, 0, 0,
gray_b*r, gray_b*g, gray_b*b, 0, 0,
0, 0, 0, 1, 0,
offset_r, offset_g, offset_b, 0, 1
 };
};
imgatt.SetColorMatrix(&matrix, ColorMatrixFlagsDefault, ColorAdjustTypeBitmap);
int iWidth = img.GetWidth();
int iHeight = img.GetHeight();
graphix.DrawImage(
&img,
Rect(0, 0, iWidth, iHeight),
0.0f,
0.0f,
iWidth,
iHeight,
UnitPixel,
&imgatt);
graphix.ReleaseHDC(this->GetDC()->m_hDC);
 }
}
渲染图片测试

posted @
2008-01-05 14:01 小四 阅读(708) |
评论 (0) |
编辑 收藏
摘要: 表达式求值的关键点在于中缀表达式转后缀表达式,算法书上都有明确介绍就不多说了。动手实现了一个表达式解析器,支持括号、多位整数以及表达式合法性判断。今天的状态实在很差,本想对表达式进行合法性判断的时候使用一些类似哈希表的技巧,比如使用一个大的bool数组,合法字符ASC码对应的项设置为1,比如可以直接判断CHARS['+']是否为true,省去查找的时间。后来发现一共就支持那几个字符,这样做未免有点...
阅读全文
posted @
2008-01-04 19:59 小四 阅读(737) |
评论 (0) |
编辑 收藏二叉排序树,又称二叉查找树,左子树结点值一律小于父结点,右子树结点值一律大于父结点,查找平均算法复杂度为O(logn)。
还是那道统计单词数目的题目,使用二叉排序树来解决,查找和插入以及统计数目使用一个函数解决,比使用哈希表的优势在于,中序遍历输出结果,单词是有序的。
程序中需要注意的地方,释放树结点的时候,要使用后续遍历,先释放子结点后才释放根结点。
/**//* -------------------------------------------------------------------------
// 文件名 : binarytree.h
// 创建者 : dj
// 创建时间 : 2008-1-1
// 功能描述 : 二叉排序树
// -----------------------------------------------------------------------*/
#ifndef __BINARYTREE_H__
#define __BINARYTREE_H__
#define SAFE_DELETE(p) {if(p) { delete [] (p); (p) = NULL;}}
struct TreeNode
{
TreeNode(const char* s):
counter(1), left(NULL), right(NULL)
{
name = new char[strlen(s)+1];
strcpy(name, s);
}
~TreeNode()
{
SAFE_DELETE(name);
}
char* name;
int counter;
TreeNode* left;
TreeNode* right;
};
class BinaryTree
{
public:
BinaryTree():m_pRoot(NULL)
{}
~BinaryTree()
{
FreeTree(m_pRoot);
}
void Lookup(const char* sName)
{
TreeNode** p = &m_pRoot;
while(*p)
{
int cmp = strcmp(sName, (*p)->name);
if (cmp<0)
p = &((*p)->left);
else if (cmp>0)
p = &((*p)->right);
else //found the word
{
((*p)->counter)++; //increase the counter
return;
}
}
// not found, then add the word node.
TreeNode* pNode = new TreeNode(sName);
*p = pNode;
}
void Dump(const char* sFile)
{
ofstream f(sFile);
Travel(m_pRoot, f);
f.close();
}
private:
void Travel(TreeNode* pNode, ofstream& f)
{
if (!pNode)
return;
Travel(pNode->left, f);
f<<pNode->name<<" "<<pNode->counter<<endl;
Travel(pNode->right, f);
}
void FreeTree(TreeNode* pNode)
{
if(!pNode)
return;
FreeTree(pNode->left);
FreeTree(pNode->right);
delete pNode;
}
private:
TreeNode* m_pRoot;
};
#endif //__BINARYTREE_H__
int main(int argc, char* argv[])
{
BinaryTree tree;
ifstream f("c:\\ip.txt");
string s;
while(f>>s)
{
tree.Lookup(s.c_str());
}
tree.Dump("c:\\stat.txt");
return 0;
}
posted @
2008-01-01 21:49 小四 阅读(467) |
评论 (0) |
编辑 收藏
折半查找又叫二分查找,要求查找表本身必须是有序的。查找算法复杂度为O(logn)。C标准库提供折半查找的库函数,声明如下
bsearch(const void *, const void *, size_t, size_t, int (__cdecl *)(const void *, const void *));
最后一个参数要求一个指向比较函数的指针。程序设计实践上写道,为bsearch提供一个key就这么费劲,写一个好的通用的排序程序也不容易,即使这样,使用bsearch而不是自己另外写仍然是个好主意。
多年的历史证明,程序员能把二分检索程序写正确也是很不容易的(Over the years, binary search has proven surprisingly hard for programmer to get right)。
于是自己用模板写一个折半查找函数,写好一个十几行的程序,也不是看上去那么简单的事情。
template<typename T>
int binarysearch(const T* tab, int ntab, const T& value)
{
int low = 0;
int high = ntab;
while(low <= high)
{
int mid = (low+high)/2;
if(value<tab[mid])
high = mid - 1;
else if (value>tab[mid])
low = mid + 1;
else
return mid;
}
return -1;
}
测试程序
int main(int argc, char* argv[])
{
int a[] = {2, 4, 6, 7, 8, 9, 13};
int aa = sizeof(a);
int n = binarysearch(a, sizeof(a)/sizeof(a[0]), 4);
cout<<n<<endl;
return 0;
}
posted @
2008-01-01 17:59 小四 阅读(1119) |
评论 (0) |
编辑 收藏
摘要: 写了一个哈希表模板类,用于统计一篇文章中不同单词出现的次数。哈希表使用char*作为key,使用桶式链表指针数组(指向结点链表的指针数组)来索引,字符串哈希函数是在网上搜来的。模板参数一个是值类型,另一个NBARREL是指针数组的大小,通常是越大哈希值冲突就越少,结点链表长度也就越短,当然查找就越快。
为了方便统计,为哈希表增加了一个IncValue函数,提高效率。统计的时候使用了快速排序,为了...
阅读全文
posted @
2007-12-30 15:13 小四 阅读(586) |
评论 (0) |
编辑 收藏在程序设计实践上看到这个简单的快速排序,用模板重新写了一遍,加深一下印象。平均算法复杂度为O(nlogn)。
其中寻找支点元素pivot有多种方法,不同的方法会导致快速排序的不同性能。根据分治法平衡子问题的思想,希望支点元素可以使p[m..n]尽量平均地分为两部分,但实际上很难做到。下面给出几种寻找pivot的方法。
1.选择p[m..n]的第一个元素p[m]的值作为pivot;
2.选择p[m..n]的最后一个元素p[n]的值作为pivot;
3.选择p[m..n]中间位置的元素p[k]的值作为pivot;
4.选择p[m..n]的某一个随机位置上的值p[random(n-m)+m]的值作为pivot;
按照第4种方法随机选择pivot的快速排序法又称随机化版本的快速排序法,在实际应用中该方法的性能也是最好的。本程序使用第4种方法。要求节点类型支持比较运算符。
template<typename T>
void quicksort(T* v, int n)
{
if (n<=1)
return;
int last = 0;
int pivot = rand()%n;
swap(v, 0, pivot);
for (int i = 1; i < n; i++)
{
if (v[i]<v[0])
swap(v, ++last, i);
}
swap(v, last, 0);
quicksort(v, last);
quicksort(v+last+1, n-last-1);
}
template<typename T>
void swap(T* v, int i, int j)
{
T tmp = v[i];
v[i] = v[j];
v[j] = tmp;
}
随手写一个不太好看的测试程序

struct str
{
str(const char* a)
{
assert(a);
v = new char[strlen(a)+1];
strcpy(v, a);
}
str(const str& a)
{
assert(a.v);
v = new char[strlen(a.v)+1];
strcpy(v, a.v);
}
~str()
{
delete [] v;
}
void operator = (const str& a)
{
if (this == &a)
return;
assert(a.v);
delete [] v;
v = new char[strlen(a.v)+1];
strcpy(v, a.v);
}
bool operator == (const str& a) const
{
return (strcmp(v, a.v)==0);
}
bool operator > (const str& a) const
{
return (strcmp(v, a.v)>0);
}
bool operator < (const str& a) const
{
return (strcmp(v, a.v)<0);
}
char* v;
};
int main(int argc, char* argv[])
{
int* array = new int [10];
for(int i = 0; i < 10; i++)
array[i] = rand();
quicksort(array, 10);
for(i = 0; i < 10; i++)
{
cout<<array[i]<<endl;
}
str s[] = {"bd", "e", "ba", "a"};
quicksort(s, 4);
for(i = 0; i < 4; i++)
{
cout<<s[i].v<<endl;
}
return 0;
}
posted @
2007-12-29 14:31 小四 阅读(445) |
评论 (0) |
编辑 收藏复习一下数据结构,用链表实现了一个堆栈模板类。
写的过程中用到一些知识点,碰到一些问题,随手记下来。
1:mystack<int> s; mystack<int> s2 = s;
编译器会把s2 = s编译成拷贝构造函数s2(s),此时调用的是拷贝构造函数,而不是赋值函数(切记)。
另外有时候编译器这种自做聪明,自动调用符合参数类型的构造函数会带来很难发现的错误,为了防止编译器这么做,可以在构造函数声明前加explicit关键字。
2:不改变成员变量值的函数,例如empty(),要声明为const,这点很重要,不然当一个const mystack&类型的对象调用empty()的时候,会编不过。
3:拷贝构造函数最好要先判断是否是拷贝自身,不然有时候就出错。
4:拷贝构造函数也别忘了成员变量初始化列表。
template<typename T>
class mystack
{
public:
mystack();
mystack(const mystack& src);
~mystack();
bool push(const T& data);
T pop();
bool empty() const;
void clear();
mystack& operator = (const mystack& src);
private:
void copystack(mystack& dst, const mystack& src);
struct stacknode
{
T data;
stacknode* pnext;
};
stacknode* phead;
};
template<typename T>
mystack<T>::mystack():phead(NULL)
{}
template<typename T>
mystack<T>::mystack(const mystack<T>& src):
phead(NULL)
{
copystack(*this, src);
}
template<typename T>
mystack<T>::~mystack()
{
clear();
}
template<typename T>
void mystack<T>::clear()
{
while(!empty())
{
pop();
}
}
template<typename T>
void mystack<T>::copystack(mystack& dst, const mystack& src)
{
stacknode* p = src.phead;
mystack<T> tmp;
while(p)
{
tmp.push(p->data);
p = p->pnext;
}
while(!tmp.empty())
{
dst.push(tmp.pop());
}
}
template<typename T>
mystack<T>& mystack<T>::operator=(const mystack& src)
{
if (this == &src)
return *this;
clear();
copystack(*this, src);
return *this;
}
template<typename T>
bool mystack<T>::empty() const
{
return(phead == NULL);
}
template<typename T>
bool mystack<T>::push(const T& data)
{
stacknode* p = new stacknode;
if (!p) return false;
p->data = data;
p->pnext = phead;
phead = p;
return true;
}
template<typename T>
T mystack<T>::pop()
{
assert(!empty());
T data;
data = phead->data;
stacknode* tmp = phead;
phead = phead->pnext;
delete tmp;
return data;
}
int main(int argc, char* argv[])
{
mystack<int> s;
for (int i = 0; i < 1000; i++)
s.push(rand());
mystack<int> s2(s);
while(!s2.empty())
{
cout<<s2.pop()<<endl;
}
return 0;
}
posted @
2007-12-27 13:15 小四 阅读(446) |
评论 (1) |
编辑 收藏