在实际生产环境中,Java作为吃CPU和内存的大户,总是少不了运维人员为TA操心,(笑。本文以Linux以及Oracle JDK的组合简单描述如何使用Linux指令和JDK提供的系统监控工具,在线上环境中获取内存和进程/线程信息,也会在其中穿插介绍Linux的常用指令和常见的系统问题排查方法。
先看下我们平时会遇到的问题有哪些?
0. 常见的系统异常
1. OutOfMemoryError , 堆内存不足,一般为大量的对象未被gc回收导致
2. StackOverflow , 栈空间不足,一般为大量的递归调用导致超过最大栈深或者栈内存的最大容量
3. Lock Contention , 锁竞争,一般表现为共享资源的争夺
4. CPU占用过高,多种原因,可能为系统本身就是CPU密集型
5. 网络IO/磁盘IO/磁盘容量占用过高,多种原因,可能为系统之间的通信异常和日志读写异常等
通常线上系统异常都需要通过系统日志来进行问题的定位和排查,如果日志的刷新频率较低,可以使用直接进行系统操作,并跟踪日志刷新的方法来查看后台日志。
tail 命令可以查看文本的最后十行记录(也可以通过 -n 参数来设置行数),通过添加 -f 参数也可以实时观察文本的当前写入,如
tail -f /fzsens/tomcat/logs/2015-11-05.log
这样在2015-11-05.log在被不断写入的同时,也可以在终端中实时监控到日志的内容,直到输入Ctrl+c 中断。
如果需要将日志下载本地进行分析,建议先将日志压缩之后再再下载,因为日志文本的重复字符较多,具有很高的压缩比,压缩之后下载可以节约大量的时间。常用的解压缩和压缩命令可以使用tar命令
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
如果系统在运行过程中出现突然没有响应或者响应缓慢,需要查看系统的资源使用情况主要包括 IO,CPU,内存等主要资源的使用情况,主要使用的指令有vmstat、top、ifconfig、top等
1. 查看磁盘的基本信息
# df 命令可以查看磁盘的基本信息
df -lh
可以查看磁盘的分区以及空间占用比,Linux的磁盘都是使用文件目录的管理方式并没有类似Windows的D/C盘的概念,通过根目录"/",可以到达任意的位置。
#查看当前目录的各个文件夹的大小
du -h --max-depth=1 ./
其中的./ 表示当前目录,--max-depth=1 表示显示的文件夹深度。显示的效果和对应的字段都比较简单,可以在机器上进行实验。
2. 查看磁盘io
# 显示io信息,吞吐量以kb作为单位,5秒刷新一次
iostat -dktc 5
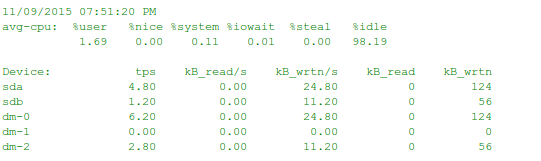
最上行为cpu信息,tps为每秒的传输次数,kB_read/s 为每秒读取,kB_wrtn/s为每秒写入,kB_read和kB_wrtn为总的读写量。以上就是平时监控磁盘信息比较关注的信息项,其他的参数和指令可以通过 man iostat 来获取,可以看到
Linux下的指令参数一般都可以通过 man 指令 来获取详细的说明。在平时使用的时候,特别是在网络使用不便的情况下,灵活使用man,来获取帮助是一个很好的办法。
2. 查看网络的io
查看网络的IO,在没有额外配置的情况下,一般需要管理员权限即为Root权限,
#iptraf 一般需要Root权限
iptraf -g
通过ifconfig 也可以查看网络的基本配置信息,和读写总量
#ifconfig 可以查看网络配置
ifconfig
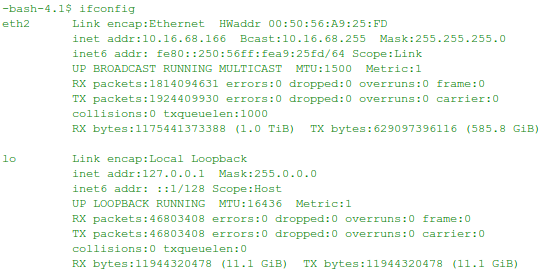
其中ethX 为网卡,可以获取对外的网卡信息,lo为本地回环地址可以获取本地访问,不经过外网的网络信息,也可以理解为localhost或者是127.0.0.1。通过RX(接收)和TX(传输)就可以知道网络的IO情况,需要运行多次,进行观察对比。
3.查看内存和Cpu信息
内存和CPU作为系统使用中最频繁的资源,一般也是出现问题的时候反应最为敏感的指标,因此也是系统监控时候需要重点关注的两个指标。
#top 为常见的获取内存和cpu的指令,默认显示为按照cpu使用率降序排序
top
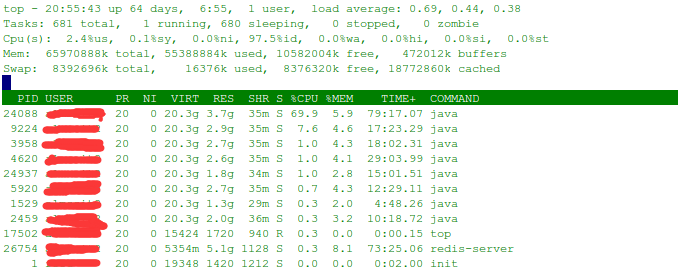
其中第一行为任务队列信息,分别为:当前时间,系统运行时间,当前登录用户,系统负载(分别为1分钟、5分钟、15分钟),通过上图可以看到系统最近一分钟负载为0.69,五分钟为 0.44,十五分钟为0.38,系统负载在正常范围内。一般我们可以取一分钟负载来作为当前系统情况的判断,偶尔超过1即为cpu占用100%也可以理解为正常现象,而取十五分钟负载作为系统稳定性的判断依据。关于系统负载可以参考文章最后的参考资料。
第二第三行为cpu信息,分别为:进程总数,正在运行的进程数,休眠进程数,停止进程数,僵尸进程数,用户cpu占比,内核cpu占比,用户通过更改进程优先级的cpu占比,空闲cpu占比,等待输入输出的cpu占比,硬件中断,软件中断,实时。一般只需要关系us和sy数据,可以反映出此时cpu的占用情况,分析是系统原因还是用户原因导致的cpu异常。
第四第五行为内存信息,分别为:物理内存总量(土豪机器..),使用的物理内存总量,空闲内存总量,内核缓冲,文件交换区,使用的交换区,空闲交换区,缓存交换区。一般需要关注使用的物理内存总量和使用的交换区总量,来作为内存使用的指标。
列表中为进程的内存和cpu使用情况,分别为进程id【PID】,进程使用者用户名【USER】,优先级【PR】,Nice值【NI】,进程使用的虚拟内存总量(VIRT=SWAP+RES)【VIRT】,进程使用的物理内存总量【RES】,共享内存大小【SHR】,进程状态(D-不可终端的休眠状态;R-运行;S-休眠;T-停止/跟踪;Z-僵尸进程)【S】,cpu占比【%CPU】,内存占比【%MEM】,使用cpu总时间【TIME+】,命令名【COMMAND】。
top命令默认会自动进行刷新,并按照cpu的占比排序,可以通过shift+m调整为按照内存占比排序,通过shift+p调整为按照cpu占比排序。
4. 查看具体某一个进程打开文件,以及网络连接的信息
# lsof 全程为list open files
lsof -p PID
将命令中的PID替换为需要查看的进程ID(可以通过ps指令和top指令查询得到),即可以得到该进程所打开的所有文件,(在Linux系统中,所有的东西包括进程和文件甚至硬件和网络,都会分配对应的文件描述符。通过文件可以访问所有的计算机资源),通过打开的文件就可以分析进行和系统其他文件之间的关联关系,如果打印的东西较多,可以使用>> 符号将输出重定向到文本中,如 lsof -p 2488 >> 2488.txt ,查看2488就可以查看数据的内容。
5. 查找进程的PID和杀死进程
# 查看系统中所有的Java进程
ps -aux | grep java
| 符号为管道符号,通过管道可以将前部分的输出内容作为后半部分的输入内容,常用语查询和过滤。ps -aux 指令用于显示所有的进程信息,将输出的进程内容通过管道传输到grep java 指令进行过滤,查看进程中包含java关键字的进程。
# kill -9 强制终止进程
kill -9 PID
通过kill -9 再结合查询到进程号,可以将进程终止,一般用于强制停止服务。
6. 其他常用的Linux指令
#cd 进入目录,用于在不同的目录中进行跳转
# ./ 表示当前目录 ../ 表示上一级目录 /表示根目录
# 进入当前目录的logs文件夹
cd ./logs
# pwd 显示当前所在目录,用于查看自己所在的目录层级
pwd
# ls -la 查看当前目录的文件和文件夹信息
ls -la
# rm 删除文件,如果需要删除文件夹需要加上 -r,强制删除-f
# 强制删除logs以及logs的子文件
rm -rf ./logs
# mv 移动文件,也可以用于重命名
# 将2015.log 更改为 2015.log.bak
mv ./2015.log ./2015.log.bak
# cp 复制文件
# 复制文件到上一级目录
cp ./2015.log.bak ../
# ~ 登陆目录
cd ~
7. 文本编辑
文本的编辑,正常推荐使用vim,使用emacs的同学,为了更好地工作请
打开 emacs,编辑 ~/.vimrc,退出emacs,愉快地使用vim,(逃跑)# 使用vim打开文件
vim filename
进入编辑模式输入 i,使用光标使用hjkl,退出和保存使用 :wq,vim编辑器非常强大,学习曲线也较为陡峭,可以参考参考文末的链接或者自己找一些资料进行查找和练习。
如果临时使用又不习惯使用vim可以使用nano进行替代
#nona 打开文件
nano fileName
使用ctrl+x可以退出编辑并选择保存。
以上即为Linux下常用的用于文件操作和系统监控的指令的简单介绍,Linux和Windows的设计理念并不一样,图形化功能较弱。一般都作为服务器使用,命令行操作虽然比较繁琐却是运维的一项基本功。需要不断得练习才可以熟练使用。
下一篇再介绍使用jdk自带的工具,进行系统问题的进一步分析和定位。
1. http://blog.scoutapp.com/articles/2009/07/31/understanding-load-averages
2. http://www.dotblogs.com.tw/ghoseliang/archive/2015/01/21/148217.aspx
3. http://blog.sina.com.cn/s/blog_46dac66f010005kw.html